scanf與stdin
在一個美好的coding日,你希望可以從stdin中讀取一個數字以及一個字元,於是你寫了下面這段code:
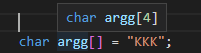
1 |
|
並輸入了32\nX做為測試(‘\n’代指換行),卻發現他的輸出不是|32 X|,而是|32 \n|
發生了甚麼事
因為scanf(“%c”)在執行期間會「無條件」吃下下一個字元並返回,而scanf(“%d”)也不會將使他中斷讀取的字元移出stream,造成scanf(“%c”)吃到原本要讓%d中斷的字(也就是’\n’)
幾種可行的解決方法
告訴scanf省略掉下一個垃圾字元再做%c:
1
2
3
4
5
6
7
8
9
10
int main(void){
int a=0;
char c='-';
scanf("%d %c",&a,&c);
printf("|%d %c|", a, c);
return 0;
}用一個空的scanf(“%c”)吸收掉垃圾字元:
1
2
3
4
5
6
7
8
9
10
11
12
int main(void){
int a=0;
char c='-';
scanf("%d",&a);
scanf("%c", &c);
scanf("%c", &c);
printf("|%d %c|", a, c);
return 0;
}用一個空的其他function吸收掉垃圾字元:
1
2
3
4
5
6
7
8
9
10
11
12
int main(void){
int a=0;
char c='-';
scanf("%d",&a);
fgetc(stdin);
scanf("%c", &c);
printf("|%d %c|", a, c);
return 0;
}
scanf的行為
scanf在看到不同的conversion format,會有不同的反應,而正是這些處理方法的不同導致了奇怪的結果產生。下面分別討論scanf %d跟%c的反應:
scanf(“%d”)
在看到%d時,scanf會略過所有的換行/空白字元,直至碰到第一個非換行/空白字元才開始讀取,並讀取直到碰到下一個非數字字元、換行/空白字元並結束,並留下使他結束讀取的那個字元在stream;
如果碰到的第一個非換行/空白字元不是數字(範例2),scanf函數**會整個結束掉(包括後續的讀取)**,且不會設置errno(perror出來是Success)
範例1 :現在input stream裡面有
"\n\n 32X \n",則scanf(“%d”)以後他會讀取到32這個數字,input stream剩下"X \n"(前面的”\n\n”被無視且吃掉了)範例2 :現在input stream裡面有
"\n XD\n \n",則scanf(“%d%c”)以後他會在讀到’X’的時候發生錯誤,直接結束整行的scanf(%c也會因此讀不到東西),此時的input stream剩下"XD\n \n"
scanf(“%c”)
在看到%c時,scanf會「無條件」吃下下一個位元並返回(不管是’ ‘還是’\n’或是’\r\n’)
常常是吃到垃圾字的受害者
小測試
- 如果我們輸入”32X\n”,在一開始的程式碼也會成功喔!