ML_2021_2-1 機器學習任務攻略
機器學習任務攻略
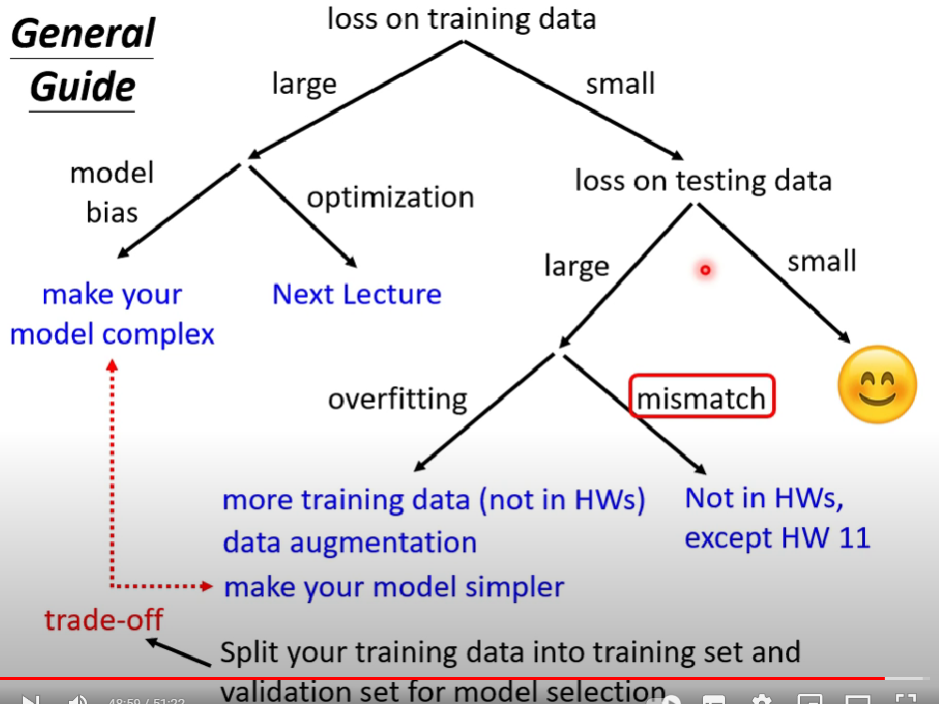
- 當有一個模型的表現不佳,有時候不一定是overfitting的問題
- 問題來源可能有數種
- Model Bias:模型本身的彈性不足,值域過小導致找不到最佳解
- Optimization Issue:模型的彈性是夠的,也就是$f^*(x)$存在,只是因為optimizer不給力,始終無法把$\theta$帶到loss更小的地方
如何分辨是model bias issue or Optimization issue?
- 以下圖為例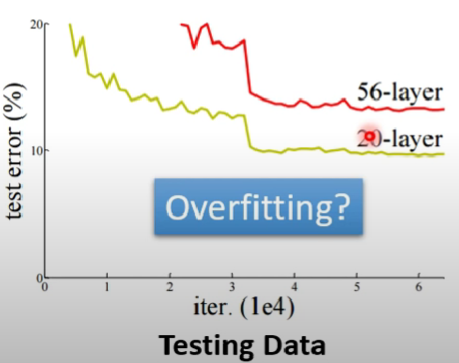
- 通常我們會認為這是模型overfitting了,才會導致層數增加反倒命中率下降
- overfitting固然有可能,但它不是唯一的可能性,我們應該要從訓練資料的loss下手
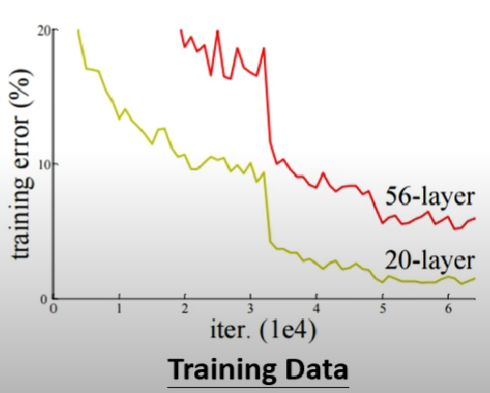
- 可以發現就算是訓練資料,56層的loss也是大於20層的,故排除overfitting的可能
- 至於模型彈性這個可能也可以排除,因為56層的複雜度>20層,故56層的loss只可能比20層還小,若是顛倒的話表示應該不是模型彈性問題,而是optimizer的鍋
- 若是發現類似優化器的問題,可以試試看先跑一些比較淺層的model或是簡易的model(如linear regression),先觀察得出來的結果
- 再跑深度的model,比較他們的結果,若深度的結果沒比較好,可以考慮換optimizer
原因樹狀圖(?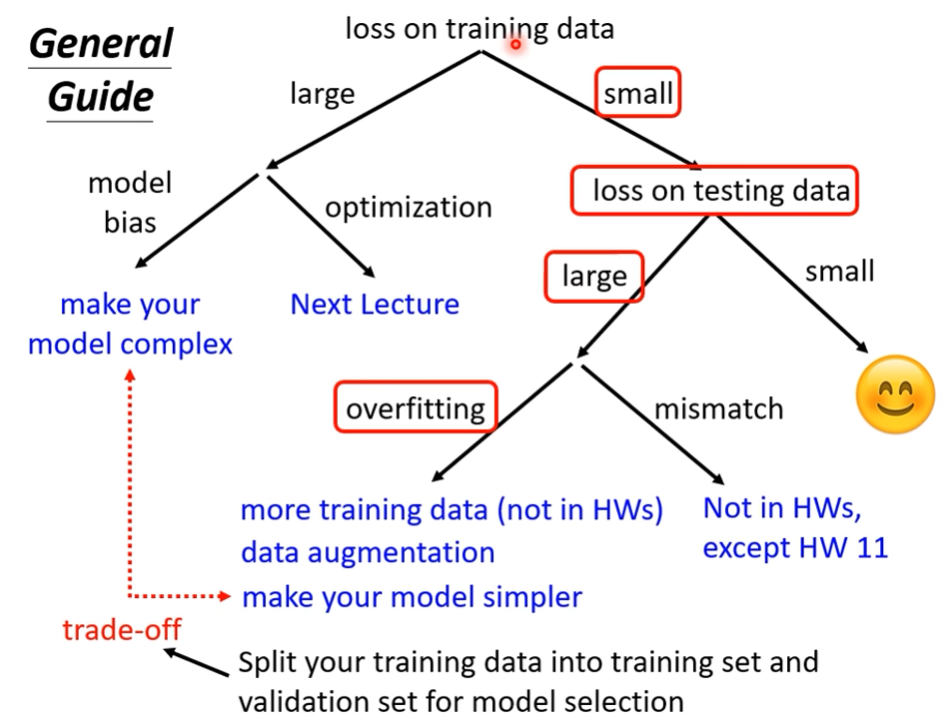
Overfitting的成因
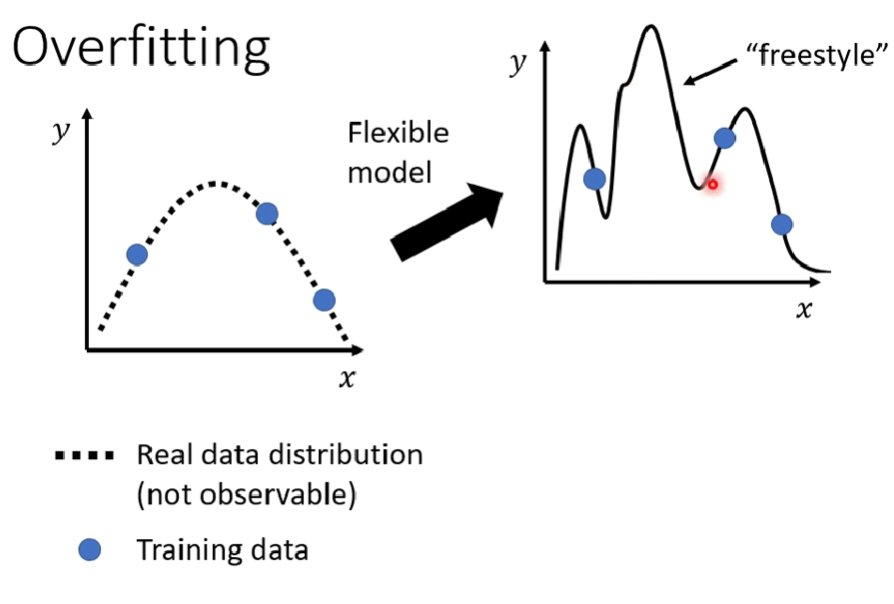
- 若訓練資料不足,模型彈性過高也可能導致overfitting(增加training data最有效)
- data augmentation也是一種方法(ex.圖片翻轉作為新資料)
- 降低模型的彈性也可以降低這個可能
- 採用一些技巧
- Early stopping
- Regularization
- Dropout
- Less features
衡量模型
- 或許某個model在所有model裡面test成績最突出,但它未必會真的是最好的模型(運氣問題)
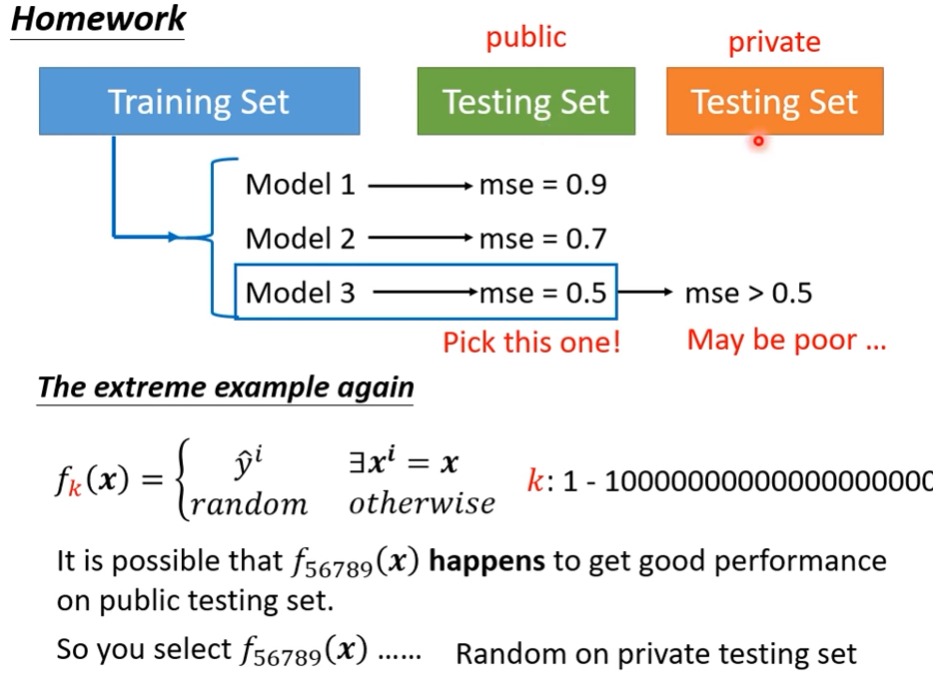
- 極端範例,一個模型剛好隨機出了最好的結果
- 所以testing set有分public跟private,避免一直上傳模型賭出最好成績
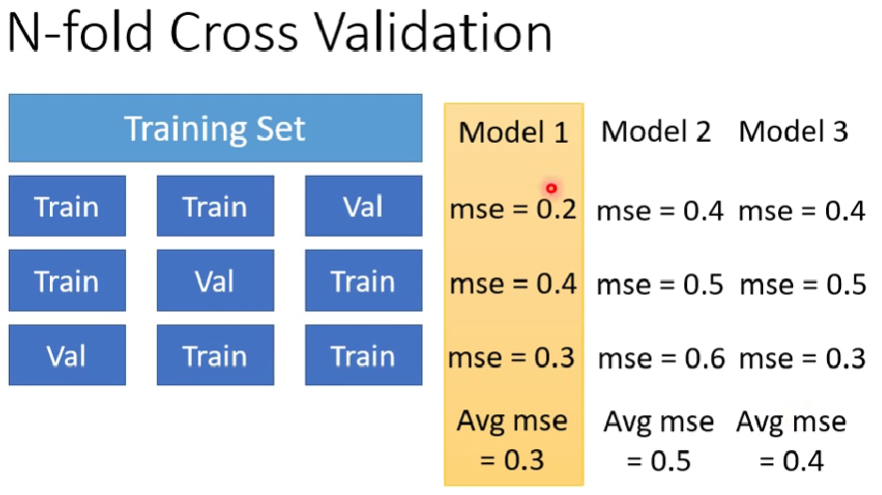
N-fold Cross Validation
- 把train set切成3份,2份是training data,1份是val data
- 交叉身分去訓練n次
data mismatch
- training data 跟 testing data有不同分布
- ex. 機器學習2020年觀看人數預測2021年觀看人數,很高可能會mismatch