ML_2021_2-3 類神經網路訓練不起來怎麼辦(二)
前言
- 之前課程(Ref. 2021版1-1)說到,在實際train data時我們不是實際把所有Data算出來對L微分求loss,而是把Data先分組切成batch,而所有batch看過一遍,才叫1 epoch
- 我們可以設定shuffle,就是每個不同的epoch,data都會重新分組
Batch size對模型之影響
- 首先比較兩個case:
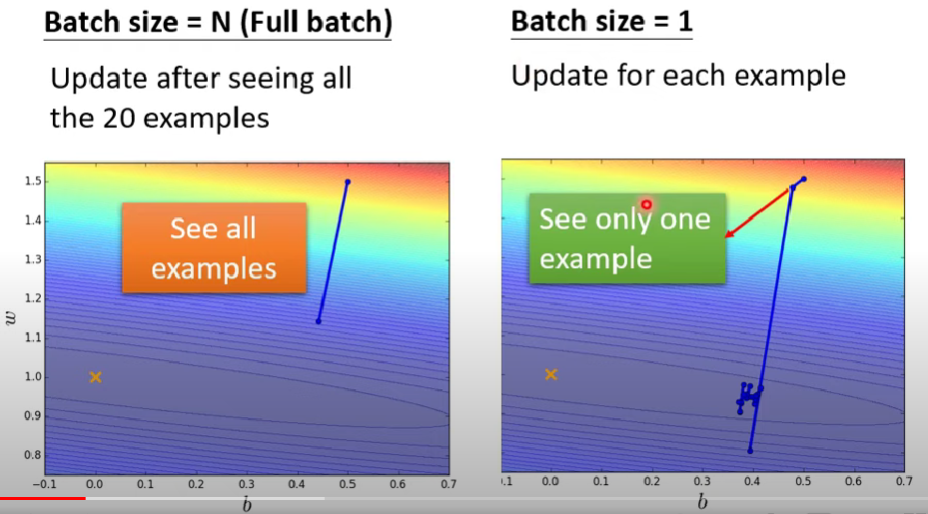
- 左邊沒有用batch,而右邊batch size = 1
- 左邊表示每次必須看完所有data,參數才能更新一次;右邊則相反,每看完一個data就更新一次參數
- 一個是重攻擊長CD,一個是輕攻擊短CD (?)
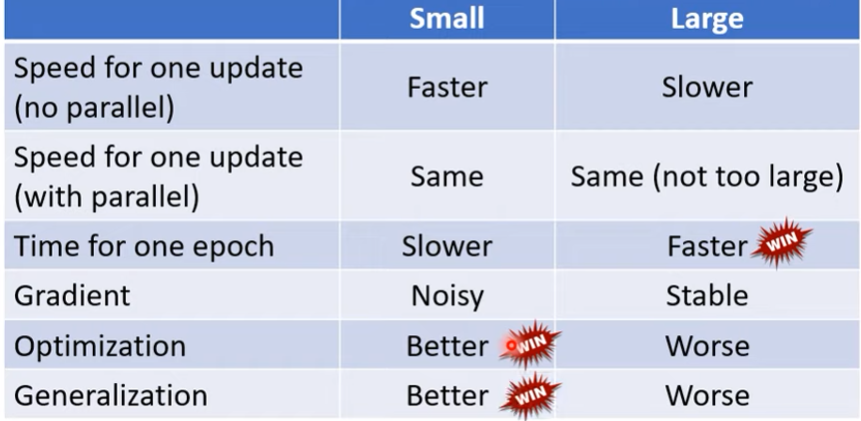
大batch優缺
優點
- 威力大(更新幅度大)且每步都很穩
缺點
- 超級慢
(小batch優缺則顛倒)
small batch or big batch?
- 兩邊看似各自相對,但我們還沒考慮平行運算
- 若考慮多核心,其實大batch不會比較慢
- 以下圖為例,用tesla V100 GPU,batch size到1000都很合適(梯度法)
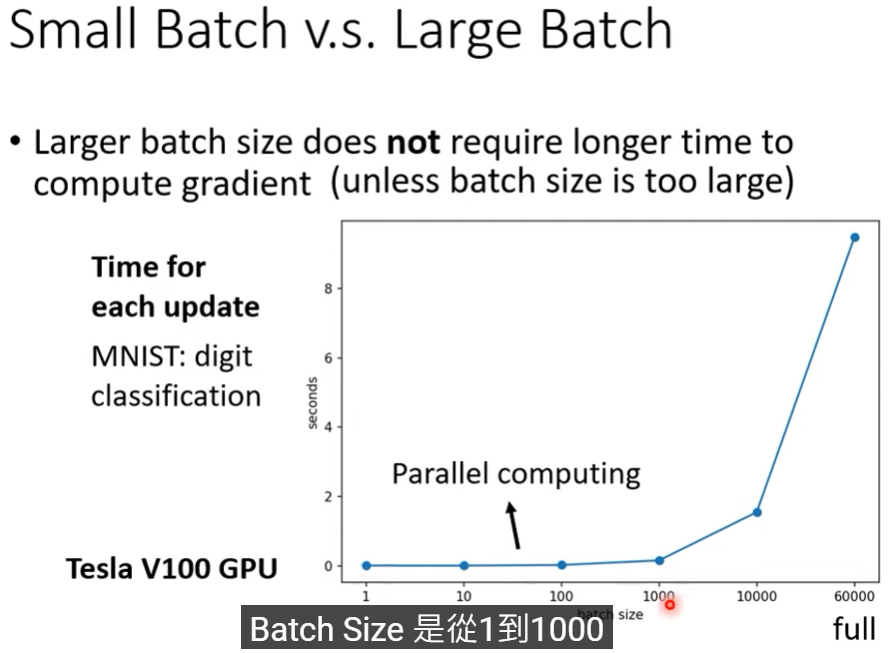
- 因為高batch不一定更花時間,所以其實在平行運算下,大batch的每epoch速度甚至還比小epoch還快
- 不過,就算是平行運算下,大batch一定比較好嗎?
- 與直覺相反的是,noisy大有時候反而可以促進訓練能力(如下圖)
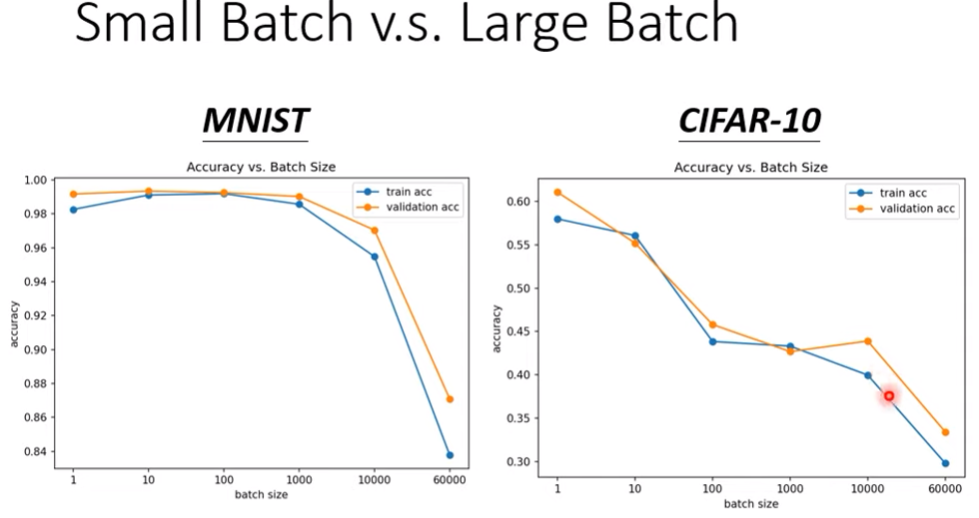
- 相同model(同bias)下,smaller batch size有更高的performance
- 問題來源於optimizer fails(Ref. 2021版2-2關於如何判定問題是哪種)
為何small batch size可以有更好的結果?
- 一說是Noisy update is better for training
見下圖
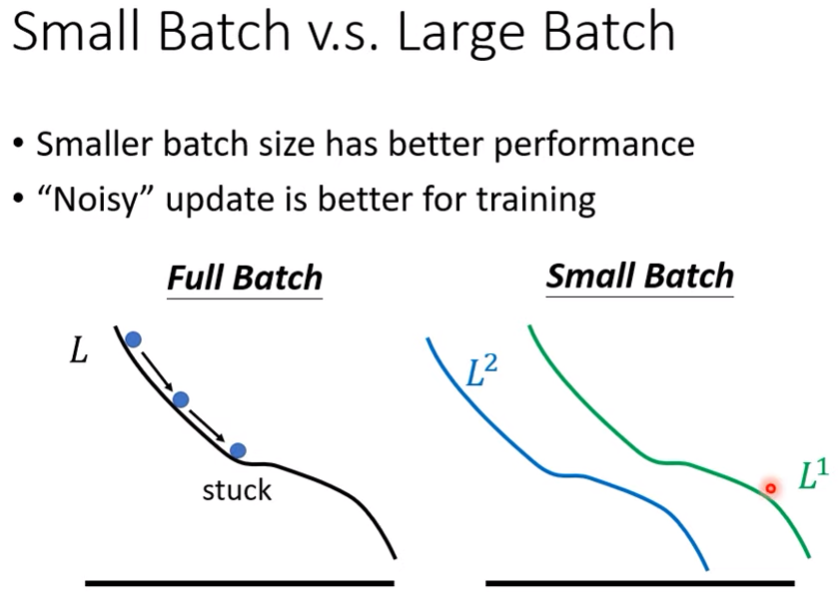
small batch下,或許$L^1$卡住了,但是因為$L^2$跟$L^1$有不小的差距,所以剛好可以讓參數更新然後把參數撞開critical point
small batch still better for testing data?
- 我們知道了small batch在training set表現更好,那testing data是否也是如此呢?
- 根據這篇論文,可以知道small batch在測試資料也有好表現
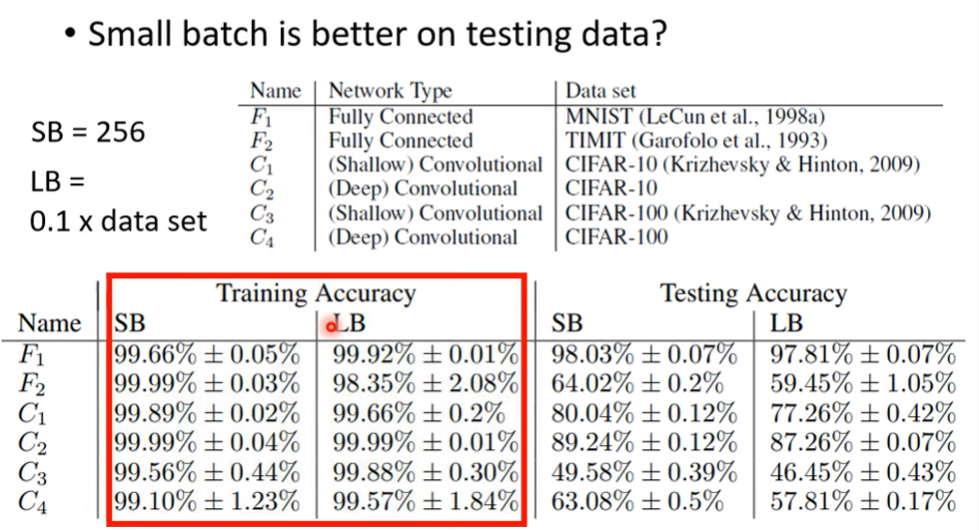
- 就算能把big batch model的準確率練到跟small batch model差不多(調hyper parameter),在測試時也會有差距顯現 $\rightarrow$ big batch有overfitting問題
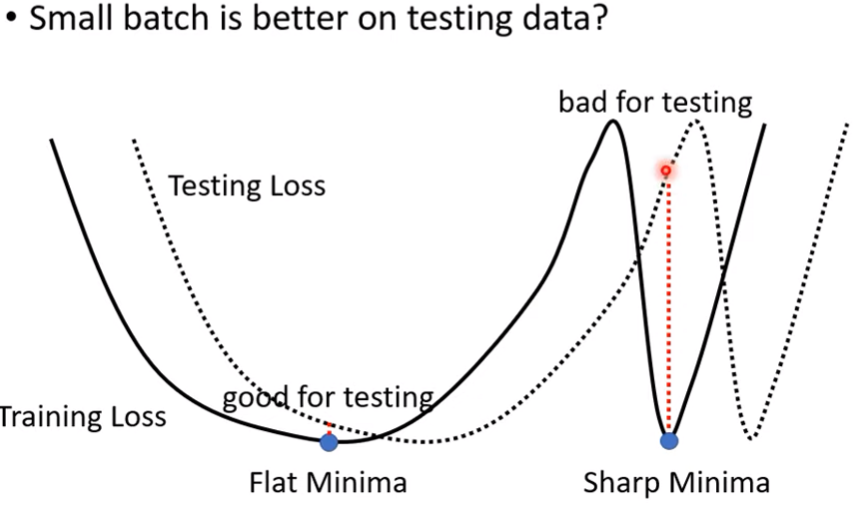
目前普遍認為的原因如下:- 就算是卡在local minima,也有分好壞
- 周圍平坦的local minima較好
- 而論文認為大batch size傾向會讓我們走向尖銳的minima point
- 一種說法是,小batch size更動頻繁走向豐富,容易走出周圍很高的minima point(對於逃離critical point能力較高),而停在平坦的minima point (Ref. 2021版2-2 鞍點)
- 因為testing 跟 training的loss function,肯定會有所小偏差,如下圖
Summary:Batch comparasion
- 因此,batch size最終成為了一個hyper parameter
魚與熊掌兼得的辦法?
- 看ref啃論文 = =
另一個對抗saddle point或minima的技術 : momentum
- 當small gradient的時候,我們走到一個鞍點或局部最小點之後就會停下來
- 但我們可以用物理式來思考,球由高處滾下來到最低點碰到上坡,不一定會停下來,因為有動能
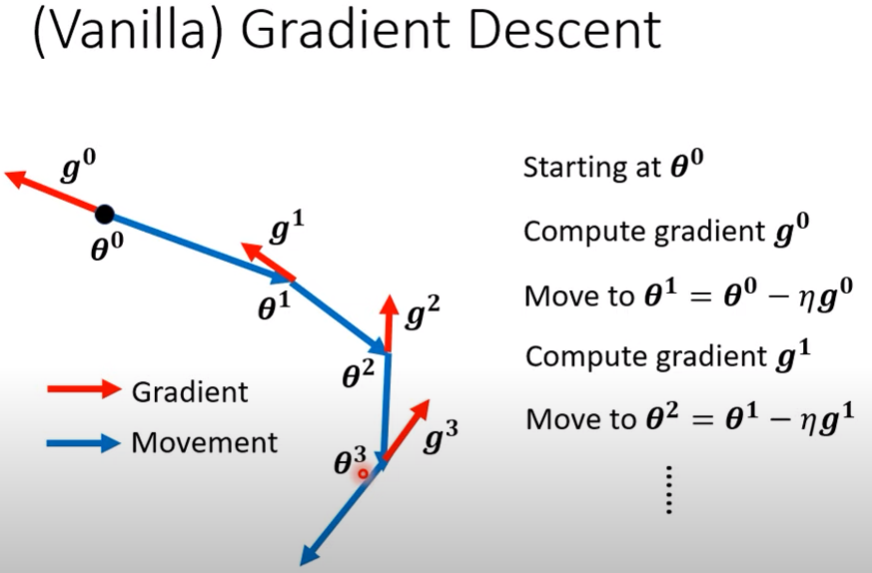
Review : 原本的梯度下降
梯度下降+momentum
- 簡單來說,就是加入慣性,額外參考上一次的移動軌跡
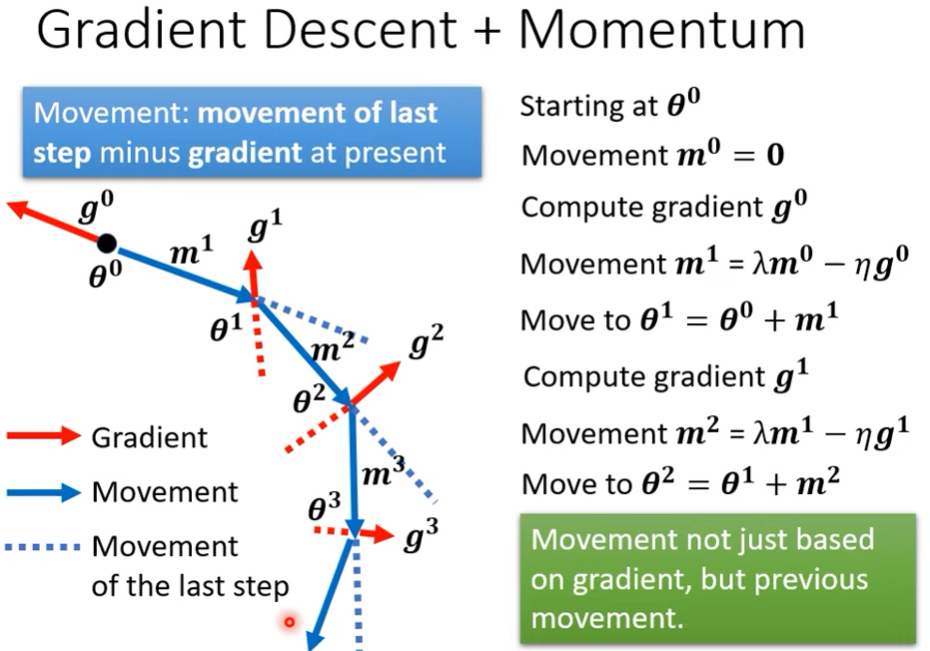
- 多了一個hyper parameter $\lambda$
