ML_2021_2-6 類神經網路訓練不起來怎麼辦(五)
- 簡短介紹Batch Normalization的技術
- 另一種直接改變error surface的技術(相對於動態lr,一種改善訓練的方法)
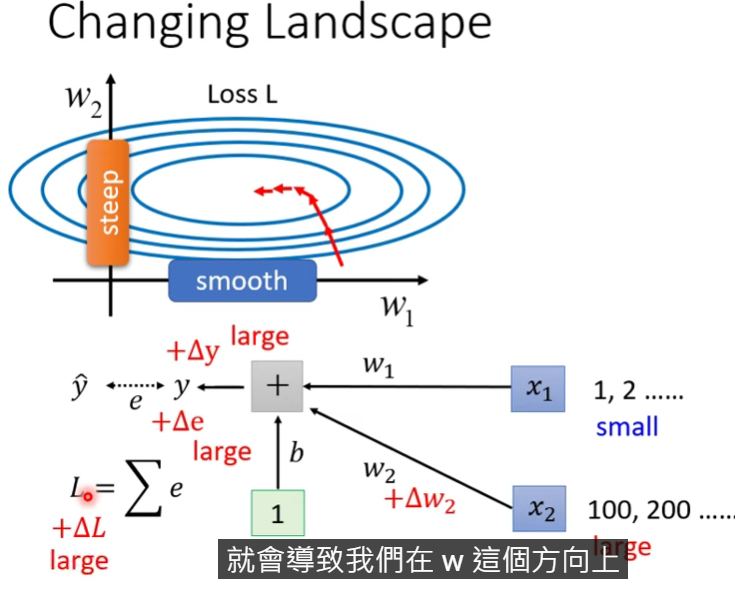
- 考慮以下模型,當$x_1$輸出很小、$x_2$輸出很大的時候,就會產生error surface橢圓的問題
- 因為$x_1$小,就算$w_1$變化很大,y的變化量也不會很大(因為相乘);$x_2$則相反
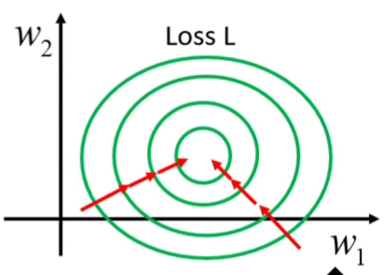
- 考慮可以把$x_1、x_2$相同的數值範圍
Feature Normalization
其中一種normalization做法
- 對多筆feature vector的同一dimention做標準化
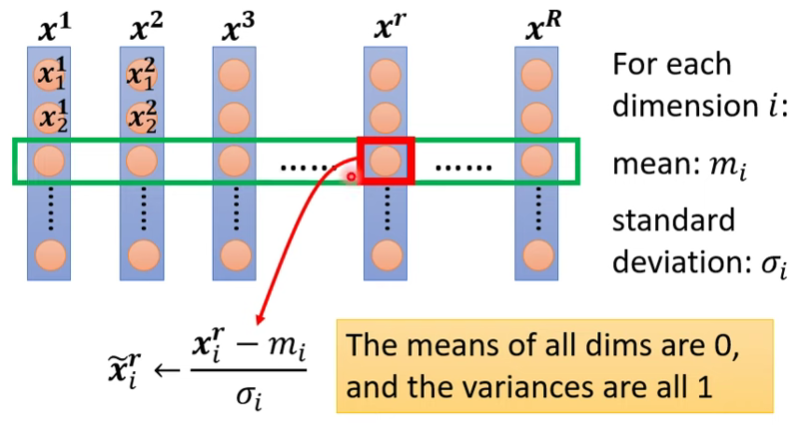
- 標準化以後,該dim的平均值=0,$\sigma$ = 1
- 像這樣就可以製造比較平衡的error surface,方便optimization作業
Case:In deep learning
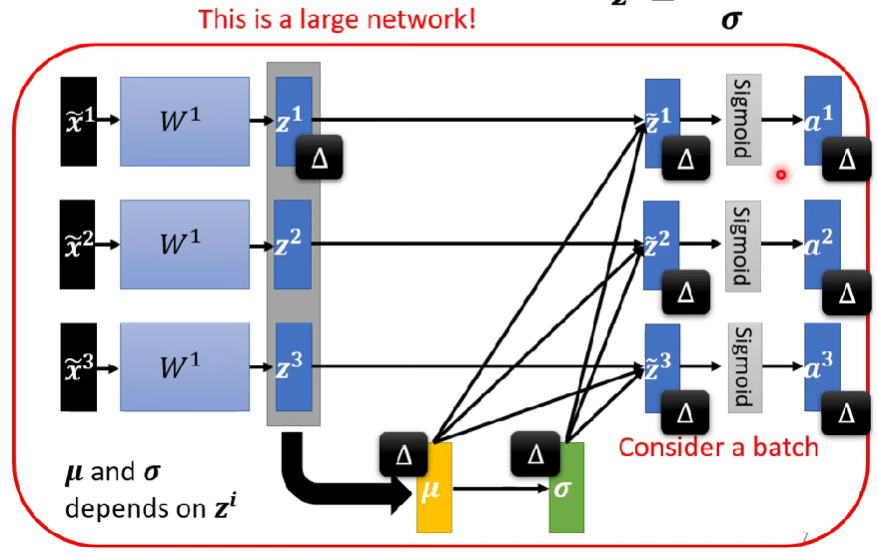
- 因為深度學習有多個層,雖然在一開始我們把x做了標準化,但是在經過一層layer計算以後,數值又失去了標準化,故我們需要進行多次的標準化
- 標準化要放在激發函數前後的影響並不大
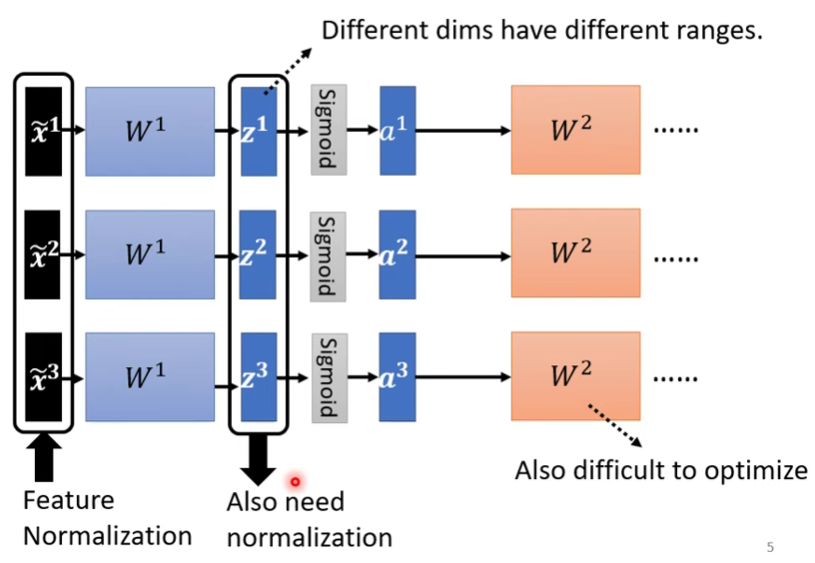
- 以上圖為例,我們需要對z再度進行標準化,公式如下(feature=3的case)
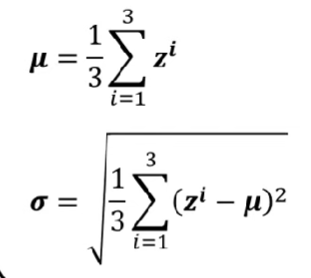
則可以得到
$$\tilde{z}^i = \frac{z^i-\mu}{\sigma}$$
後續層也依此類推 - 這個feature標準化的過程使得所有feature之間有了關聯性 -> 這是一個network
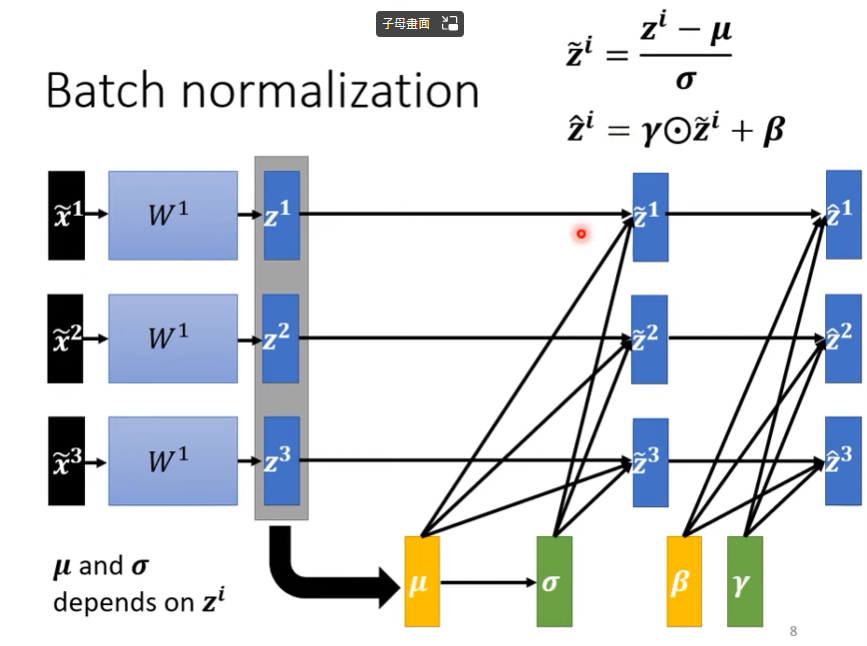
Case:training in batch approach?
- 這樣的標準化流程會跟著batch(一組batch內部做標準化)跑,不是所有feature納進來標準化
- 這樣的作法稱作batch normalization
- 問題來了,我們會需要足夠大的batch size才能做一個好的標準化(誤差會比較小)
- 問題來了,我們會需要足夠大的batch size才能做一個好的標準化(誤差會比較小)
- $\beta、\gamma$是模型的另外兩個參數,透過學習得到
- 為啥需要這兩個參數?
- 因為標準化會保證$\tilde{z}$之平均值 = 0,這樣的結果有可能會對模型產生一些負面影響,所以我們需要$\beta、\gamma$兩個參數來讓數值變成比較貼合模型需求
- 問題:這樣不就又破壞掉標準化平衡了嗎?
- 我們初始設定$\gamma = 1 , \beta = 0$,讓他們初始為真的標準化
- 讓模型來決定值該怎麼分步
Batch normalization - testing data
- 剛剛講的都是training的情況下
- testing又稱inference
- 當真的是線上模型時,我們必須每一筆資料進來就進行預測,不能用batch
- 當數據只有一筆,怎麼做normalization($\mu=? , \sigma=?$)
- 實作上的解法(pytorch):
- 在training若有用這個技術,每次batch算出來的$\mu_i , \sigma_i$就會記錄下來再做以下處理
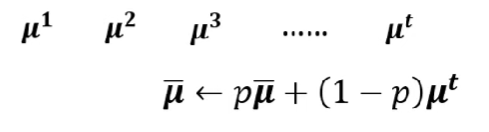
- 在training若有用這個技術,每次batch算出來的$\mu_i , \sigma_i$就會記錄下來再做以下處理
在實際test時,就代入
$$\tilde{z} = \frac{z-\bar{u}}{\bar{\sigma}}
$$
- Batch normalization的實際測試結果,連結
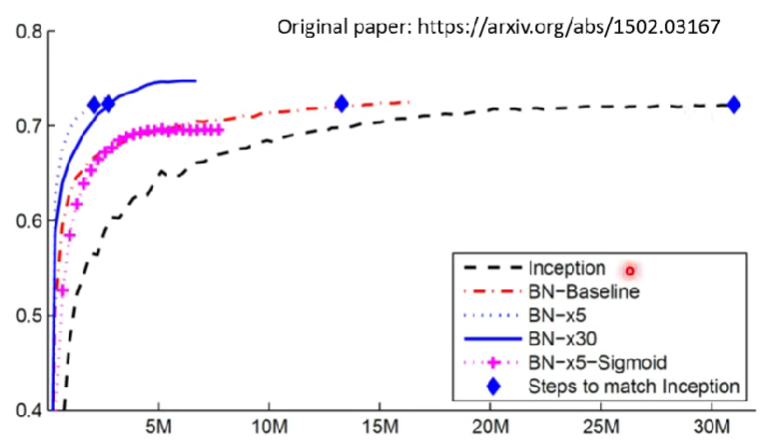
- 紅色線是有做batch normalization
- 粉色線,使用sigmoid function
- 其他線,就是lr乘上$x$倍
- 黑色沒有用BN,用inception
- 收斂速度更快,但結果差不多
How does Batch Normalization help optimization?
下面這篇論文的作者發明這個詞”Internal covariate shift”
根據這篇論文所認為有以下可能
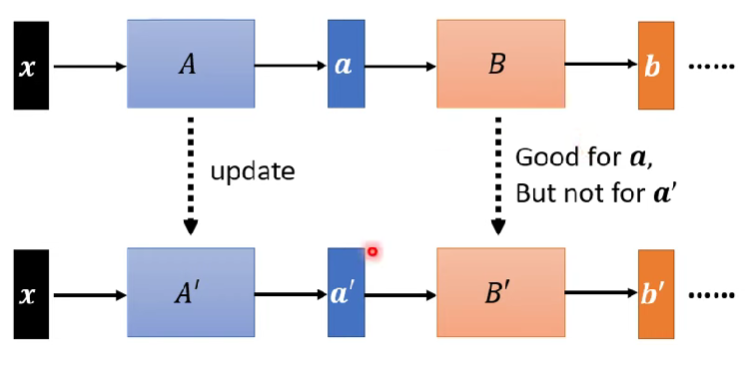
我們做參數update,將A變成A’,B變成B’,但是B的變動是根據之前算出來的a作為input,當整體更新了以後,B’要面對的input卻不再是a,而是經過A’算出來的a’,故導致仍舊失準
- 而Batch normalization的作法,是讓a跟a’有相似的分布(similar statistics),故誤差會比較接近
但是Experimental result並不支持這個緣故(打臉)
- 打臉者認為實驗下來,a跟a’的分布都差不多,而且不管分布是不是差很多,影響都不大,於是這個假說是錯的(不是batch normalization的關鍵)
- 不過實驗跟理論依然證明,Batch normalization依然會改變error surface的地貌

- 此人認為batch normalization的發現可能是偶然(意料之外)的,但無論如何這是有用的方法
- normalization有一堆方法,參考如下