ML_LEE_2022_hw3
可進行的目標
Data augmentation (training)
搜尋torchvision.transform,docs
transform.randomRotate , resize等等
最後必須要toTensor,model只吃pytorch的tensor不吃PIL library的
Adv. Data augmentation - mixed up (training)
mixup (把兩個影像混再一起,變成多重label)
cross entropy loss function需要重寫
Module selection (搜尋torchvision.models)
AlexNet
VGG系列
ResNet
SqueezeNet
Cross validation
每次訓練更換dataset
ensemble

以下是我對這作業除了Base sample code以外所做的變化,針對上述目標,有做的我才會列出來
First Approach
Note: 因為這次作業放在kaggle上寫&跑,而kaggle設計在結束比賽之前不能公開notebook,所以不能內嵌frame= =,下面只能先直接貼上code代替
Data argumentation
- 改動trains transform,新增兩個處理,一個是讓照片有0.6的可能水平翻轉,另一個則是把它做normalization
- 針對個別batch算出mean,std做normalization的方法我沒找到,目前直接套網路上常用的3 channel RGB圖之平均值當參數 (mean = [0.5,0.5,0.5] std = [0.1, 0.1, 0.1])
- 這樣做觸犯1個問題,我的normalization是單一標準對所有data做,還是對每個batch單獨這樣做?在這個case沒差,不過這是因為數字寫死,normalization做的實在有夠醜= =
- 觸犯另一個問題是,我的layer之間有沒有再進行一次normalization呢?有待釐清1
2
3
4
5
6
7
8
9
10
11
12
13mean = [0.5, 0.5, 0.5]
std = [0.1, 0.1, 0.1]
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((128, 128)),
# You may add some transforms here.
transforms.RandomHorizontalFlip(p=0.6),
# ToTensor() should be the last one of the transforms.
transforms.ToTensor(),
transforms.Normalize(mean,std),
])
- 針對個別batch算出mean,std做normalization的方法我沒找到,目前直接套網路上常用的3 channel RGB圖之平均值當參數 (mean = [0.5,0.5,0.5] std = [0.1, 0.1, 0.1])
Module selection
- 這裡我直接選用VGG11取代原本的自訂模型Classifier
Result
- 跑了至少100 epoch,結果training acc達到0.97,validate acc卻只有0.1x而且不再有更好結果,明顯的overfitting = =
- 可能要考慮加入cross validation
- 可能是data augmentation太弱?
- 可能是VGG11模型太強(彈性過高)
- 我耍笨不小心把訓練的過程輸出洗掉了,沒有圖片QQ
Second Approach
Module Selection
- 單純的把VGG11模型改回Classification
Result
- 看起來好像沒什麼變化,看來不是VGG模型導致overfitting
- 可能是normalization的部分出問題了,接下來嘗試把normalization改掉,用VGG train看看
- 如果這樣成功的話,只能說應該是normalization把數字改成詭異的形狀了,算是一種人為mismatch吧

- 如果這樣成功的話,只能說應該是normalization把數字改成詭異的形狀了,算是一種人為mismatch吧
Third Approach
Transform
- 移除normalization
Result
acc爆增回正常範圍了,看來真的是normalization的鍋qwq
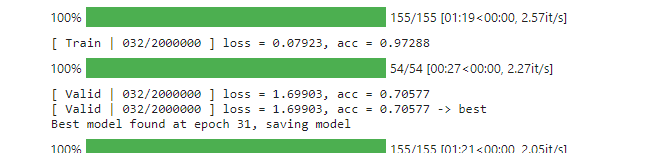
上面這是最高紀錄,valid acc 有70%,位於epoch 32,我後來一直跑到epoch 52都沒看到更好的分數,就先卡掉了(看起來進medium概率近乎於零= =)
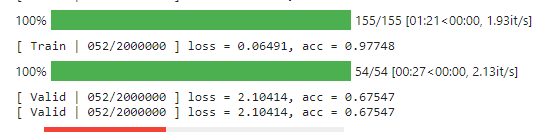
不過雖然70%比起之前的acc是大躍進,距離medium仍有一段距離,training acc也到達瓶頸,看起來是需要提高data augmentation的時候了
Forth Approach
- 偷偷參考了一下學長的筆記,發現新招數「AutoAugmentation」,適用在Transform內
- 這招的原理來自於這篇論文,可以從data裡面學到如何排Transform Augment
- 同時也從學長的筆記學到,因為code裡面有用BatchNorm2d (batch Normalization),所以batchSize大一點會比較有利
- 這好像就是元兇嗎orz,多做一次norm
- 不過我只有在助教寫的Classification有看到norm,因為用的是VGG11,所以不確定是否仍然有用norm(沒看源碼XD)
- 這好像就是元兇嗎orz,多做一次norm
Transform
- 新增
transforms.AutoAugment() - 新增
transforms.RandomRotation(degrees = 32) //rotate+-32度
BatchSize
- 修改為96
Result
- 這次讓他跑了一整晚,充分認識到kaggel save&run的重要性= =
- 直接掛網頁按run all如果網頁停止回應或是閒置過久就沒了
- 這次訓練時間大約10hr,仍然沒有得到最終結果->網頁爆了
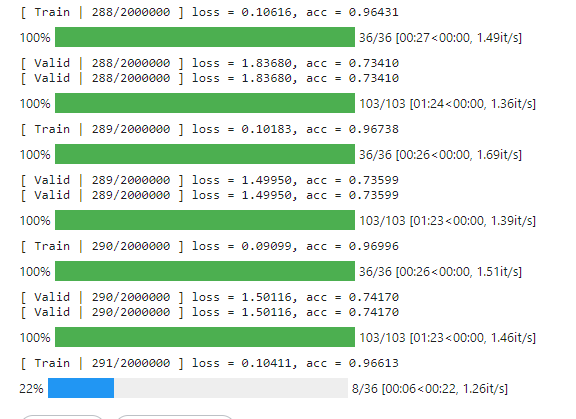
- 練到了291 epoch,感覺valid的acc就上不去了… 只能止步medium嗎
Fifth Approach
- 最後又重跑了一次training = =,沒有作任何更動,GPU quota還有18 hr 希望夠用…
Result (Finale)

= =凸
- 最終在epoch 389的時候終止了,最好的epoch在252,其實已經很接近當初的150 patience了
- 好在best model parameters有保存下來,接下來就是load model之後直接predict了
最終成果
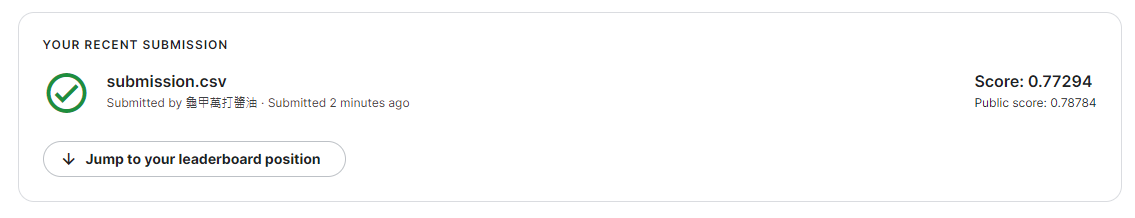
心得
這次作業是CNN的範例題,這次的圖像辨識題真的讓人思考到了如何去優化他,助教提供的sample code省去了start from scratch的痛苦,讓我們能專注在實作理論的部分
其實很多的技術(Batch normalization、crossEntropy+softmax、data Batch等等)都已經被函數包進去一次做好了,正常的時候是不會發現到他們的存在,這或許也間接印證了他們是十分有效提高命中率的方法吧。而真的需要實作的part其實不多,比較難的是要去翻出他們的document一一認識他們的結構並理解功能,這才是最難的部分
助教的sample code寫得蠻精美的,甚至有看出在自訂結構其實有保留空間讓學生自行切分training set跟valid set(可能是用於做cross validation用的),考量到讓學生改進而保留空間,真的厲害!除了實作理論與閱讀結構以外,最重要的估計就是看懂這個訓練過程的資料結構了吧~