ML_2021_5-2 Transformer(上)
- Transformer與BERT之間關係密切
- Transformer是一種seq2seq的model
seq2seq簡介
- 由模型來決定輸出要多長
- 語音辨識、機器翻譯、speech translation就是應用(Hw4做的是分類模型)
- speech translation不一定是speech recognition + machine translation,因為很多語言其實並沒有文字,或不普及(ex.台語:母湯?不行?)
- 其實有機會直接輸入台語的聲音資料,直接輸出中文(省略再翻譯的過程)
seq2seq應用
台語範例
- 直接台語轉中文不是沒有可能
- 但是對於倒裝(文法)上的不同會有問題
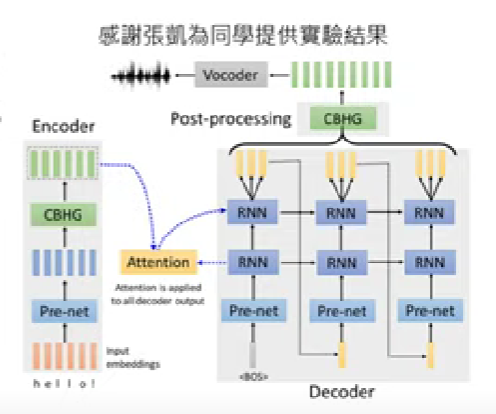
Text-to-speech(TTS) synthesis
- 相反的,也有可能輸入中文然後合成出台語的聲音訊號作為輸出(範例是分為兩步驟,先把中文翻譯為台語羅馬拼音,之後再把他轉成聲音)
seq2seq for chatbot
- Seq2seq也可以用在聊天機器人,輸入是一段文字,輸出則是response
- 學習大量的日常對話(來自影集、連續劇等)
seq2seq in NLP
- 大多數的NLP應用,都可以想成是QA問題,而QA的問題,又可以透過seq2seq model來解決
- 不過對於NLP的任務,通常還是會針對任務特性做一個客製化的模型,seq2seq就像是瑞士刀一樣,對大多問題都可用,但不是最佳模型
seq2seq in others
- seq2seq也可以在一些輸出看似不像是seq的問題套用
syntactic parsing
- ex. 文法解析(syntactic parsing)
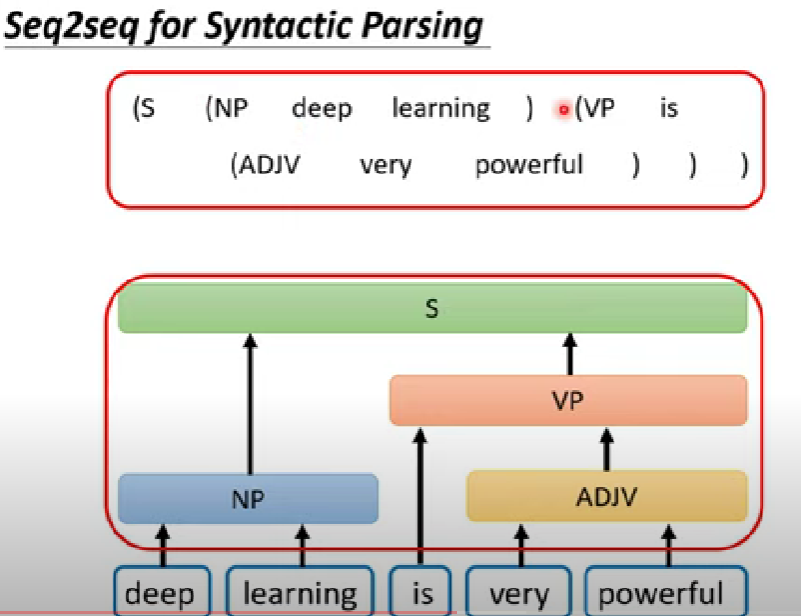
- 把一個樹狀的結構用括號硬解成一個sequence,參考
multi-label classification
- 不同於multi-class,multi-label可以屬於多個class(同時屬於好幾類)
- 每個data對應的label個數可能不同,不能直接用分類模型輸出前n名
- 硬做seq2seq,輸出sequence就是class
object detection
- 物件偵測也可以用seq2seq硬做
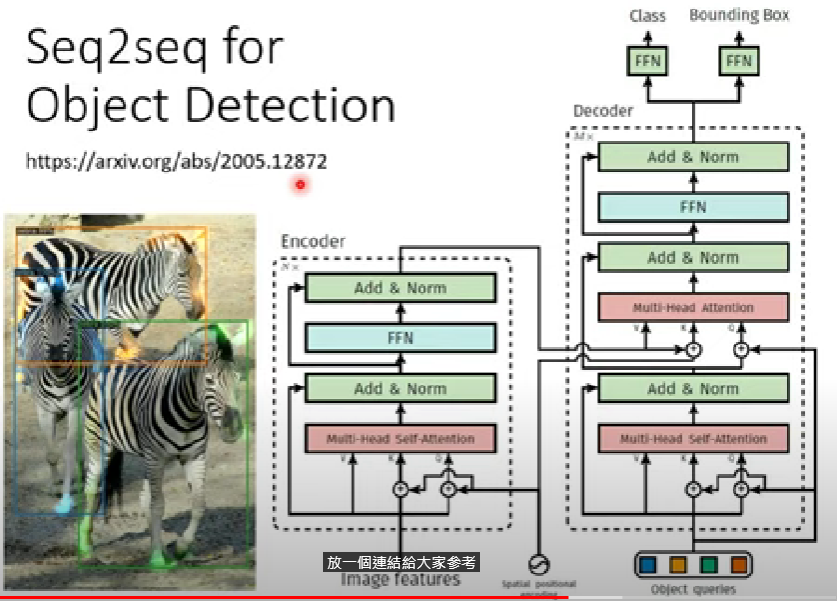
- 參考連結:End-to-End Object Detection with Transformers
Seq2seq結構
- 避免見樹不見林,先看seq2seq的完整模型架構
- 主要分為encoder跟decoder兩大區塊
- 起源來自: Sequence to Sequence Learning with Neural Networks(2014)
- 現今形狀(transformer): Attention Is All You Need(2017) (下圖)
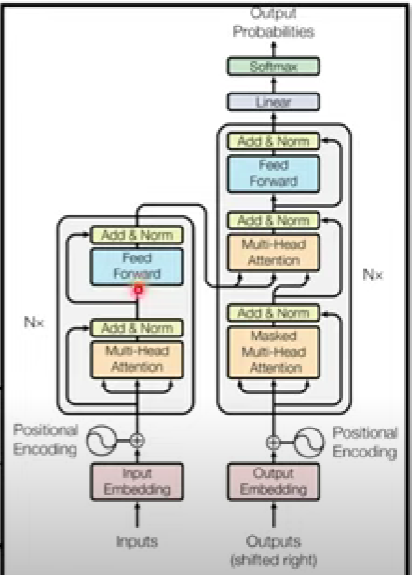
- Add & Norm = residual +layer norm
- 圈起來的地方是一個block,此圖範例只有1 block
encoder
- 給定一排向量(input),輸出一樣長度的向量
- transformer中block用的技巧就是self-attention,好幾個block就是作好幾次self-attention
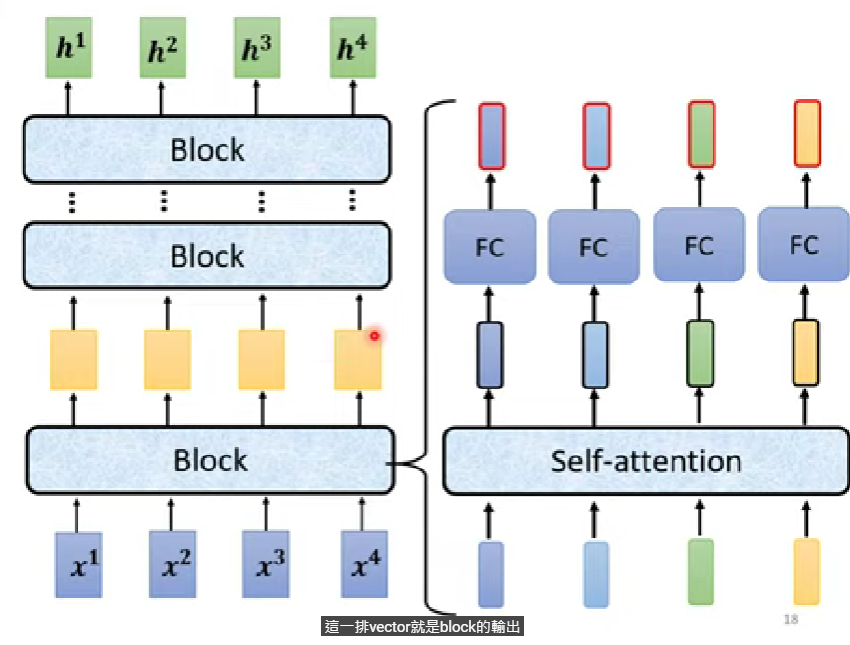
- self-attention詳細的執行過程請參考CH4
- 避免見樹不見林,這裡解釋一下encoder步驟,下方再分開講解每個區塊在幹嘛。encoder就是先把輸入轉成vectors(input embedding),做完positional encoding以後,連續做好幾個block
- 每一個block做:self-attention -> residual connection -> layer norm -> FC
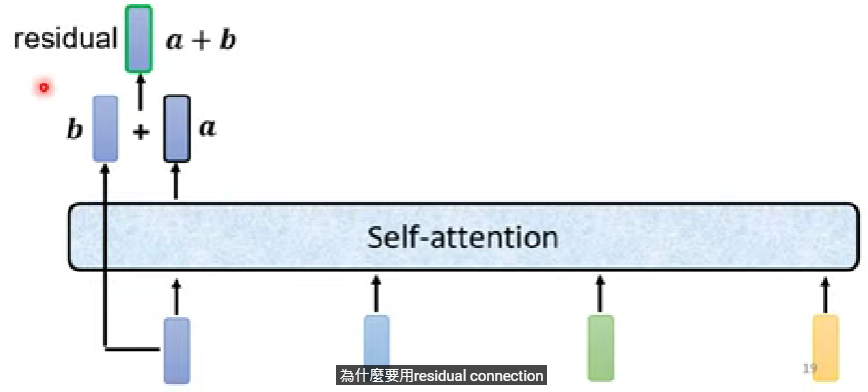
Residual connection
- 原因暫且不討論,不過這種架構在DL被廣泛應用
- 做完self-attention之後在輸入到下一個block之前,需要進行一次的residual connection,就是把self-attention的輸出再加上自己原本的輸入
Layer norm
- 原始transformer做完residual以後做layer norm,把單一feature的每個dimantion計算標準化
❗️ 與Batch norm的差別:
batch norm是把batch內不同筆data的同一個dimantion做標準化(橫向);
而layer norm則是把同一筆data內不同dimantion做標準化(豎向)
Fully connected layer
- 上述做完以後,輸出丟入FC訓練,然後『再做一次residual network以及norm』以後,輸出的結果,是一個block的計算
其他形狀的encoder
BERT其實就是transformer的encoder
encoder的network架構是按照原始論文設計
- 還有其他encoder設計
- 參考1、為何Batch norm不如layer norm?
- 還有其他encoder設計
下章節介紹decoder