ML_2021_5-3 Transformer(下)
- 接續5-2,講論文的transformer中的decoder區塊
- Decoder有兩種
- autoregressive(AT)
- non-autoregressive(NAT)
- 這堂課主講AT
Transformer:Decoder的運作 (語音辨識為範例)
輸入一段聲音,輸出一段文字
encoder收到聲音訊號(seq)以後,輸出一排vector(seq)
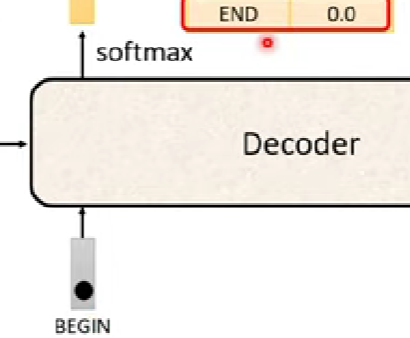
Decoder用於產生語音辨識的結果
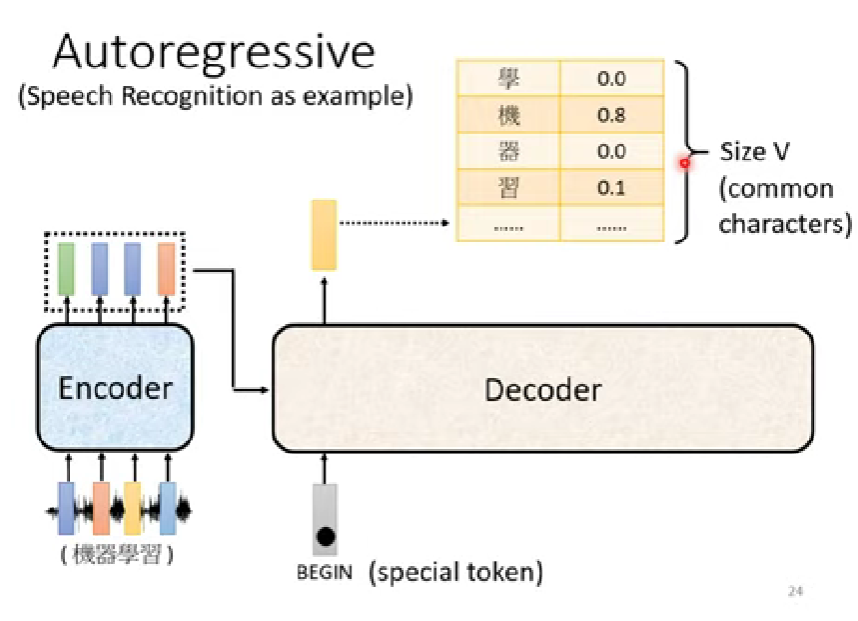
輸出會是一個向量(one-hot vector),他的長度就是整個語料庫的大小
- 中文通常就是一個字為單位,英文有可能以詞為單位,也可能以字根字首為單位(subwords)
第一步驟的時候,decoder會輸入一個token(BEGIN),一種特殊符號
接下來第二及之後的步驟,會把前面步驟輸出的字母丟入decoder作為輸入
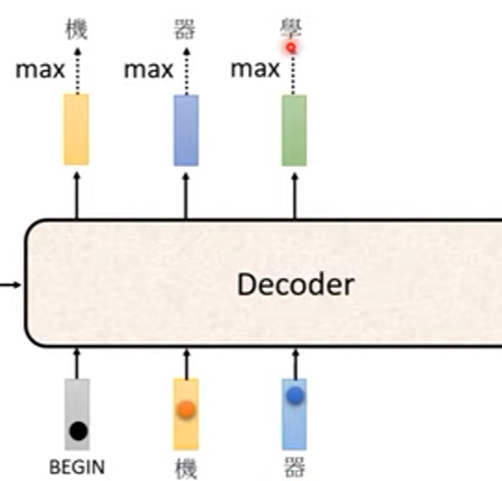
- 這樣的問題就是,如果前面辨識產生的結果是錯的,那後面的輸出也會受到錯誤的結果影響 (error propagation)
Transformer:Decoder結構
- 暫且忽略來自encoder的輸入
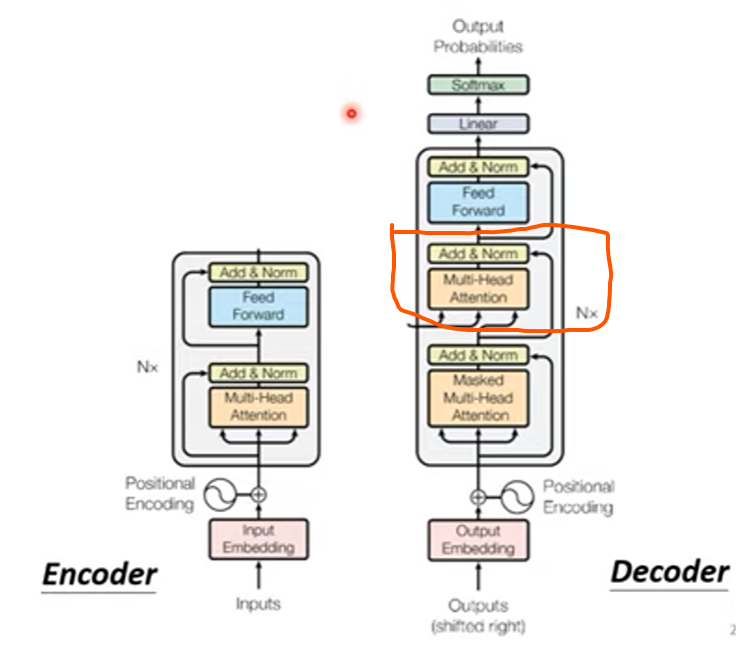
- 撇除圈起來的地方不看,可以發現decoder跟encoder的差別沒有很大
masked self-attention
- 注意到decoder第一格有一個”masked multi-head attention”
- 相對於原始的self-attention,decoder只能參考前面的vector,不能參考之後的
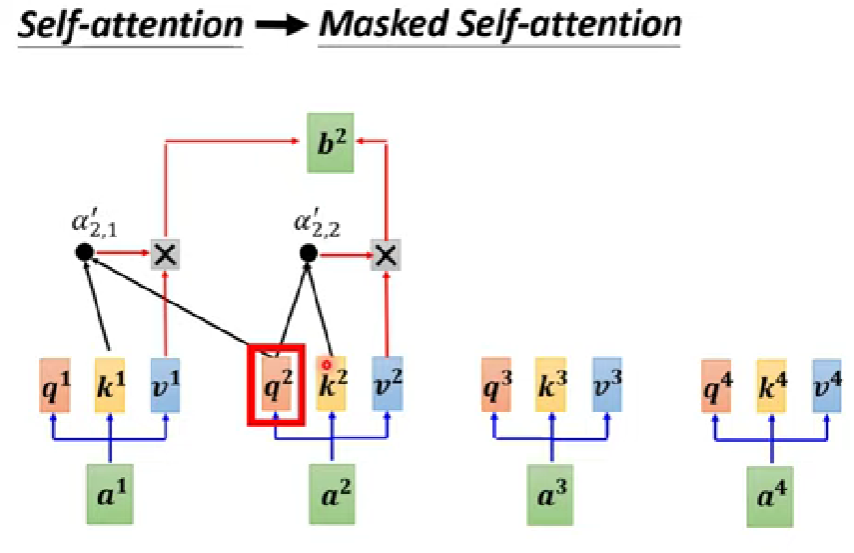
- 因為token是一個一個產生,不能考慮右邊
Determine output length
- 目前的decoder運作機制,不知道甚麼時候該停下來 (無限自動選字的概念)
- 需要有一個「斷」的token,塞在輸出的vector class內
Non-autoregressive(NAT)
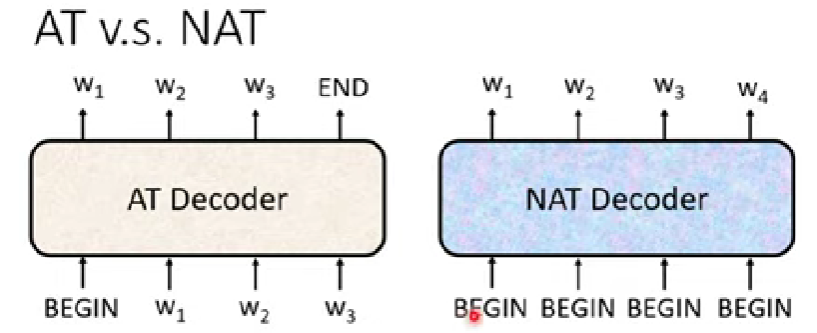
- AT會把上一個字輸出出來,才產生下一個字元
- NAT則是一次給好幾個START token,一次性產生整個sequence
Determine NAT output length
- 如何知道NAT decoder的長度哩?
- 另外做一個pridictor去預測NAT該輸出的長度
- 假設一個句子的長度上限,看哪段輸出了END,就把字串砍到那個位置
NAT優點
- 相對於AT更平行化
- 可控的輸出長度(可以不用被動等到有END)
- 可以發現AT是有點RNN、LSTM的思維
- NAT是熱門的研究主題
- 目前NAT的performance還是比較差
Transformer:Encoder-Decoder
- 現在焦點放到剛剛圖中圈起來的地方,這裡是encoder與decoder交會的地方(cross attention)
圖示如下: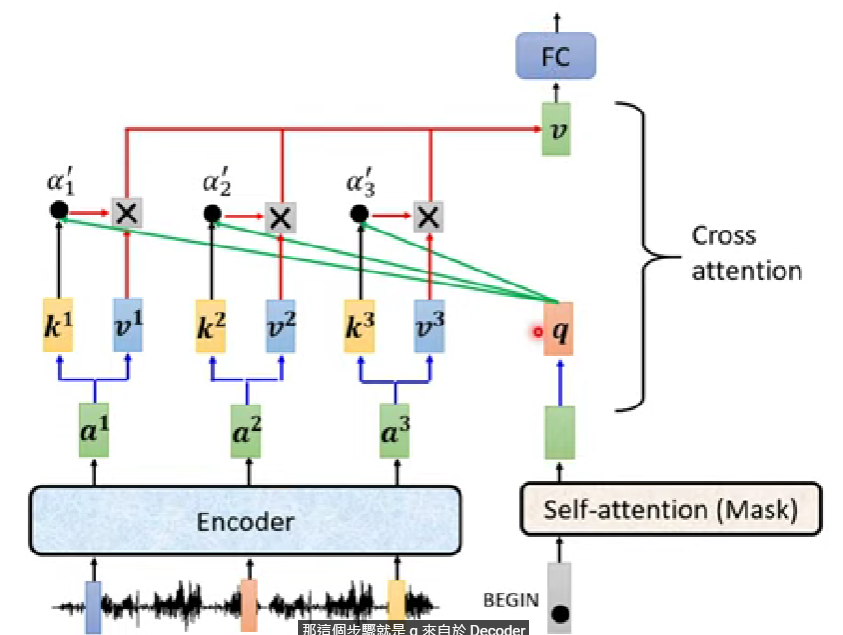
做法很像一層self-attention在做的事情,只是q來自於decoder,而k,v來自於encoder
-
- 這個方法不是來自transformer
- 是先有cross才有self
- 這個方法不是來自transformer
在原始論文內,decoder每一層cross attention都會拿encoder最後一層的輸出當輸入
- 當然也有其他種連接方式,參考
以上是模型訓練好以後,模型怎麼去跑,接下來來談seq2seq類模型在training中碰到的小問題
Seq2Seq:Training
Teacher forcing
下圖為Transformer的最終訓練展示圖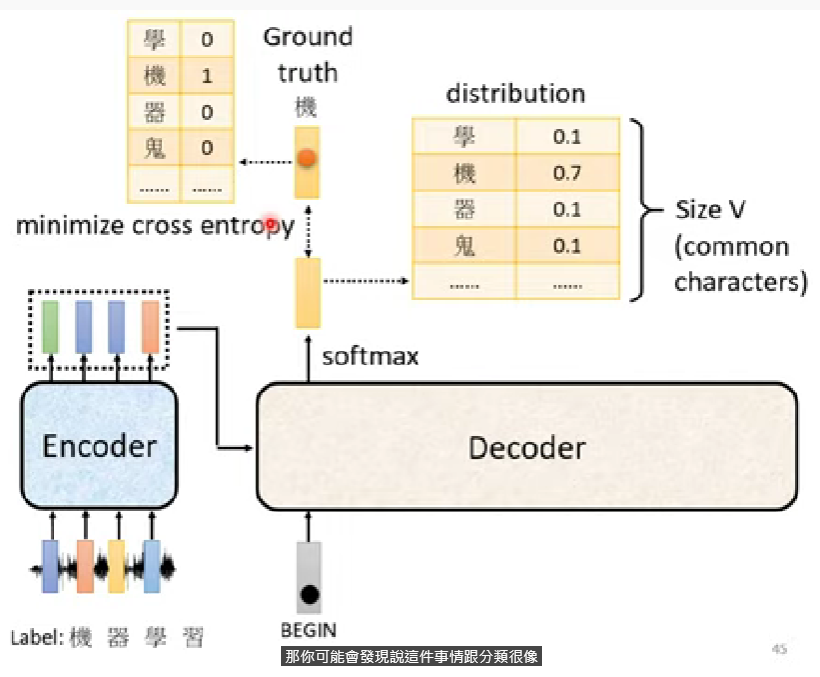
- 每一次預測一個單位字,就是做一次的分類問題
- 每一個字視為一個分類問題,所以要minimize 這些所有預測+BEGIN、END各自的cross entropy
- 在訓練的時候會給decoder看ground truth
- 這樣做法叫做Teacher forcing
Copy mechanism
- 很多任務不一定要decoder產生東西,而是從輸入中複製東西出來
- Ex. User: 你好,我是庫洛洛
Machine: 庫洛洛你好,很高興認識你
- 機器不需要知道庫洛洛是誰,只要判別出人名複製就好
- Ex. User: 你好,我是庫洛洛
- 機器聽不懂的話,也可以直接copy user input來再次詢問user是甚麼意思
- 應用: 閱讀文章的摘要
- Pointer Network、Copy network
Guided Attention
- TTS as example(語音合成)
- 看到過短的句子可能沒念完整,但讓她念好幾次卻發音成功
- 嘗試強迫機器把所有看到的東西都看一遍 -> guided attention
- 在輸出嚴格的任務中頗好用(語音合成、辨識)
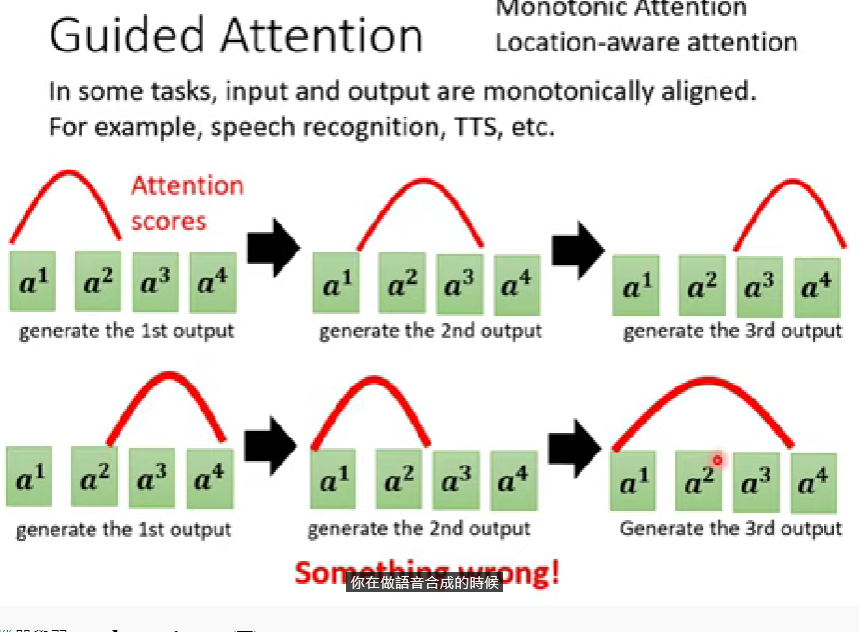
- 如果機器的觀看順序顛三倒四,表示這種attention可能會出問題
- Guided attention就是強迫機器的attention有規範(ex.由左向右)
- 相關參考:Monotonic attention、Location-aware attention
Beam search
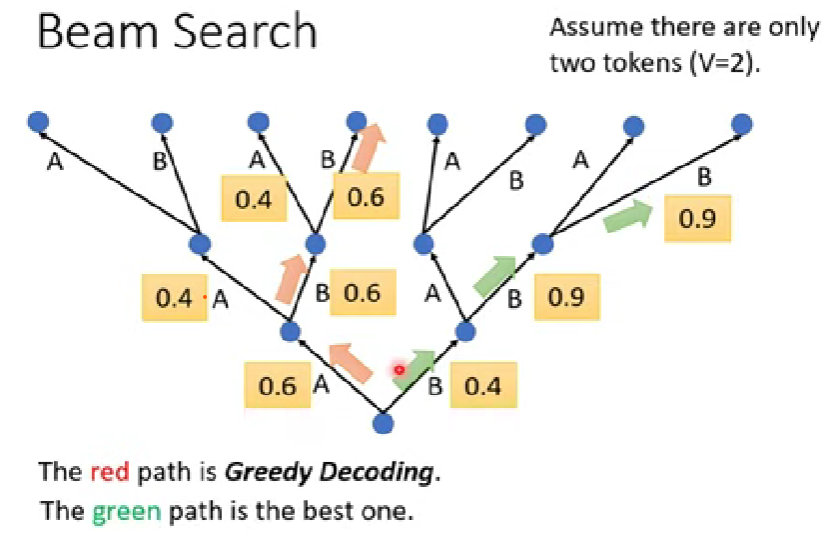
假設這個decoder只可能產生兩個token,要輸出一段sequence,前面都是直接輸出該輪概率最高的token,稱為「Greedy decoding」
但有沒有可能前面選擇非最佳的token,反倒導致後續的decode命中率更集中呢
Beam search找一個非最佳也不用爆搜的作法
關於這個演算法,有兩方論戰:The curious case of neural test degeneration
- Randomness is needed for decoder when generating seq in some tasks (ex.TTS)
老師認為在針對答案較為單一的任務,Beam search會表現比較好;而如果需要機器的想像力(空間大)的任務,則建議需要一些隨機性(故意加一些noise)
TTS任務中,需要在測試集加入雜訊
- true beauty lies in the crackks of imperfection
Optimizing evalyation metrics?
- 作業用BLEU Score作為判斷依據
- Decoder產生輸出以後,跟正確的句子做比較
- 但訓練的時候資料分開計算,只能用cross entropy。這兩者之間未必正相關
- 不一定要挑decoder cross entropy效果最好的那個模型
- 可否在training用BLEU score?
- 不容易,BLEU本身很複雜,不易微分
- 當遇到opti無法解決的問題,就用RL(強化學習)硬train一發- REF (HARD)
- 可否在training用BLEU score?
Exposure bias
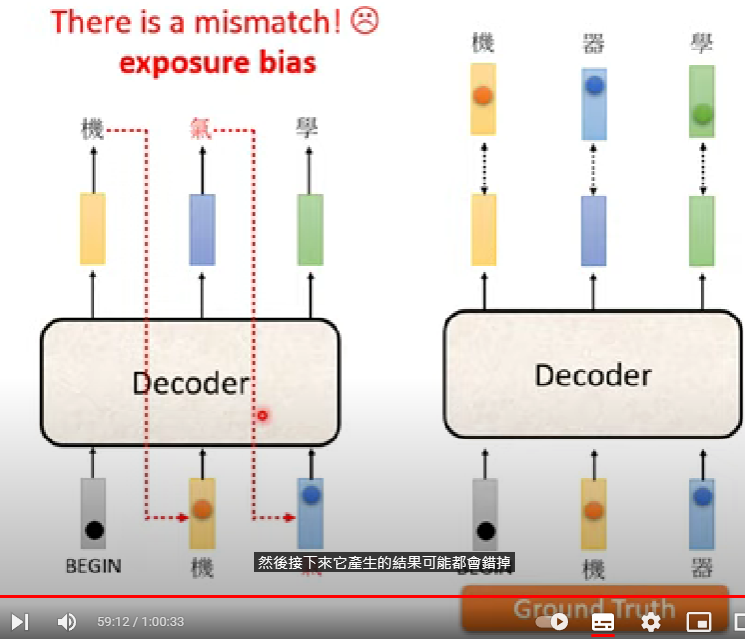
因為decoder在train的時候,前面的vector是看著ground truth在做,所以不會有「一步錯,步步錯的問題」
但當然在測試時不可能這麼做
可以故意在training裡面加入錯的ground truth來讓模型習慣前面有錯誤輸出的應對方式 -> Scheduled Sampling
在transformer中會有所變化,參考