ML_2021_6-3 生成式對抗網路(三) – 生成器效能評估與條件式生成
- GAN的訓練仍然困難,gen跟dis有一個卡住了,就整個卡住了
- Generator跟Discriminator需要互相match each other
More training GEN tips

GAN for Sequence generation
前面講的都是影像的GAN
Decoder變成了generator
Decoder的輸出一樣丟入discriminator訓練,產生分數
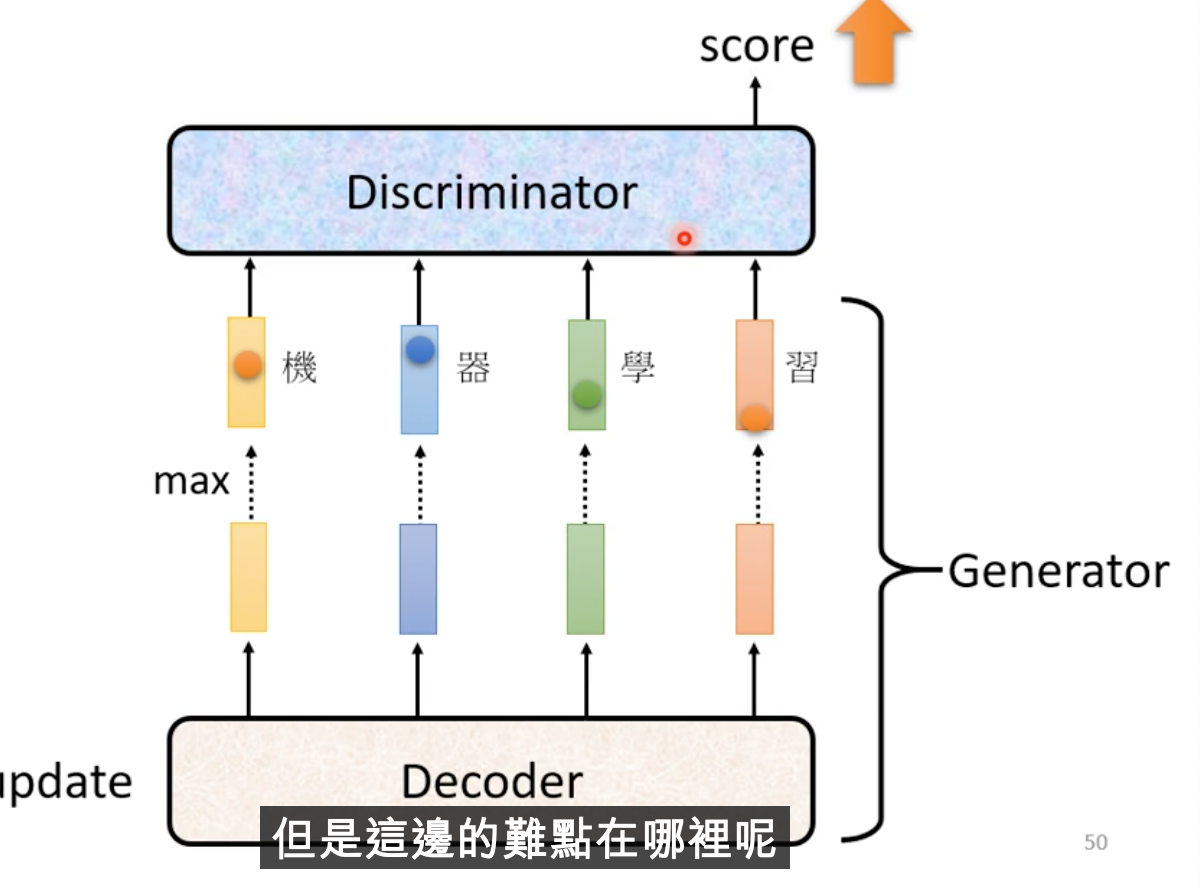
問題在於,decoder不能用梯度下降去train
- 微不出decoder weight變化對discriminator的影響(distribution不變)
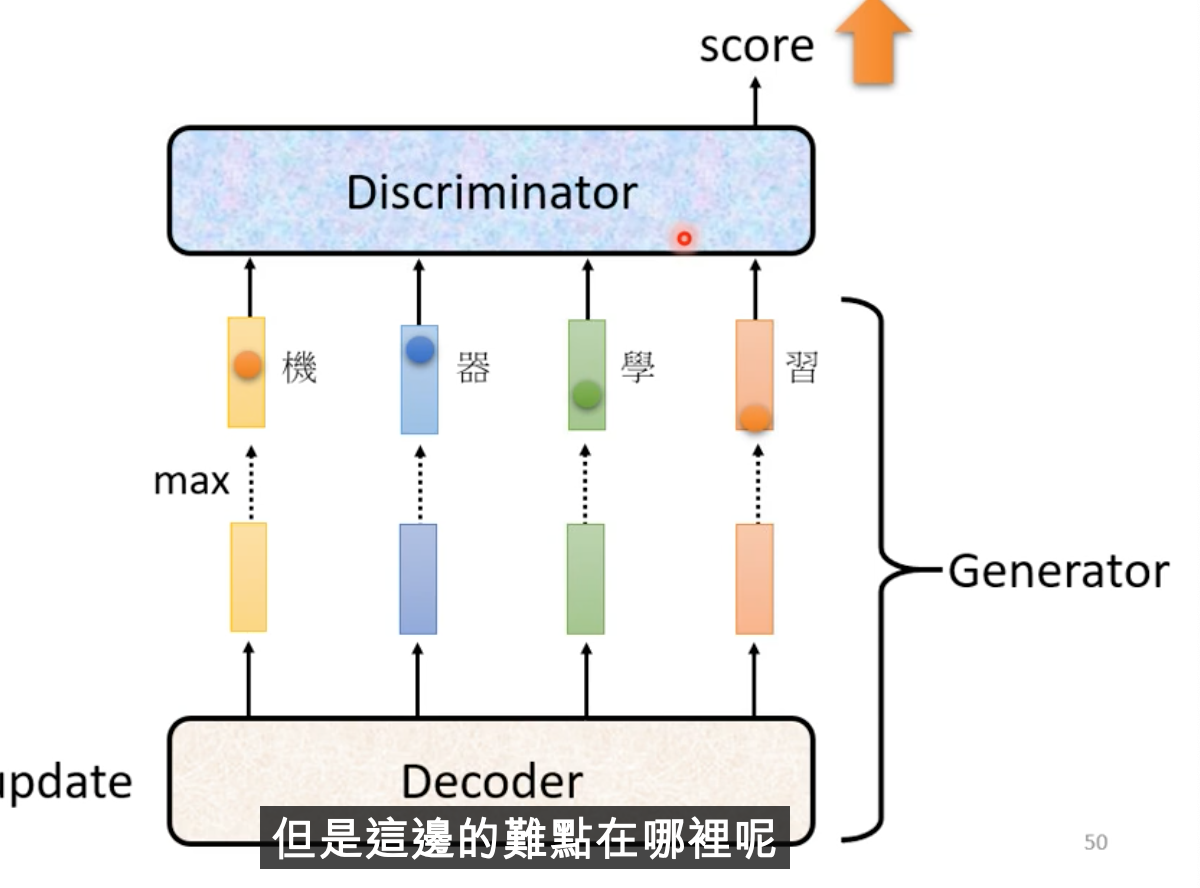
- 微不出decoder weight變化對discriminator的影響(distribution不變)
碰到很難train的地方,可以用用看RL
- RL很難train,且GAN也很難train,不好用
完整的GAN課程:連結
More generative models: VAE、FLOW-based Model
可否用supervised learning做
- 直接把正確的圖片變成vector,作為ground truth(訓練目標)
- 直接放入隨機向量來生成圖片
- 可以這樣做,但是向量不能亂取,相關文章:
Quality of GAN
如何衡量GAN的好壞
以往都是直接真人去看效果,但可能不客觀且價格昂貴
在某些任務的確可以衡量
- (作業6)提供一個動畫,看GAN能抓出幾張是人臉
分類系統,把GAN輸出的影像作為分類系統的輸入,讓這個系統分類
- Ex. GAN產生班馬,給分類系統分類該圖像是否班馬類
- 當分類越集中,則GAN的輸出「可能」越好
- 問題:Mode Collapse
Mode Collapse
- 可能GAN輸出的圖片來來去去就那幾張,過度單一,但那些圖片都剛好分類成功
- GAN知道discriminter的盲點了,就集中攻擊這個點

- 上圖的人臉過度單一
- 目前暫時無解,但看得出來
Mode Dropping
- GAN輸出的圖片看起來有一些變化性,看不出問題
- 但可能輸出的圖片只是真實圖片的一小個子集
- 不容易偵測出來
Diversity
- 衡量GAN輸出的多樣性分布

與quality差別在於,quality衡量只看一張圖片,分類越集中越好
diversity則是看一堆圖片,輸出的平均越均衡,代表多樣性越好
Inception score(IS):若good quality, diversity,則large IS
但作業不會用inception score
- 輸出都是人臉,對於IS來說diversity會很小
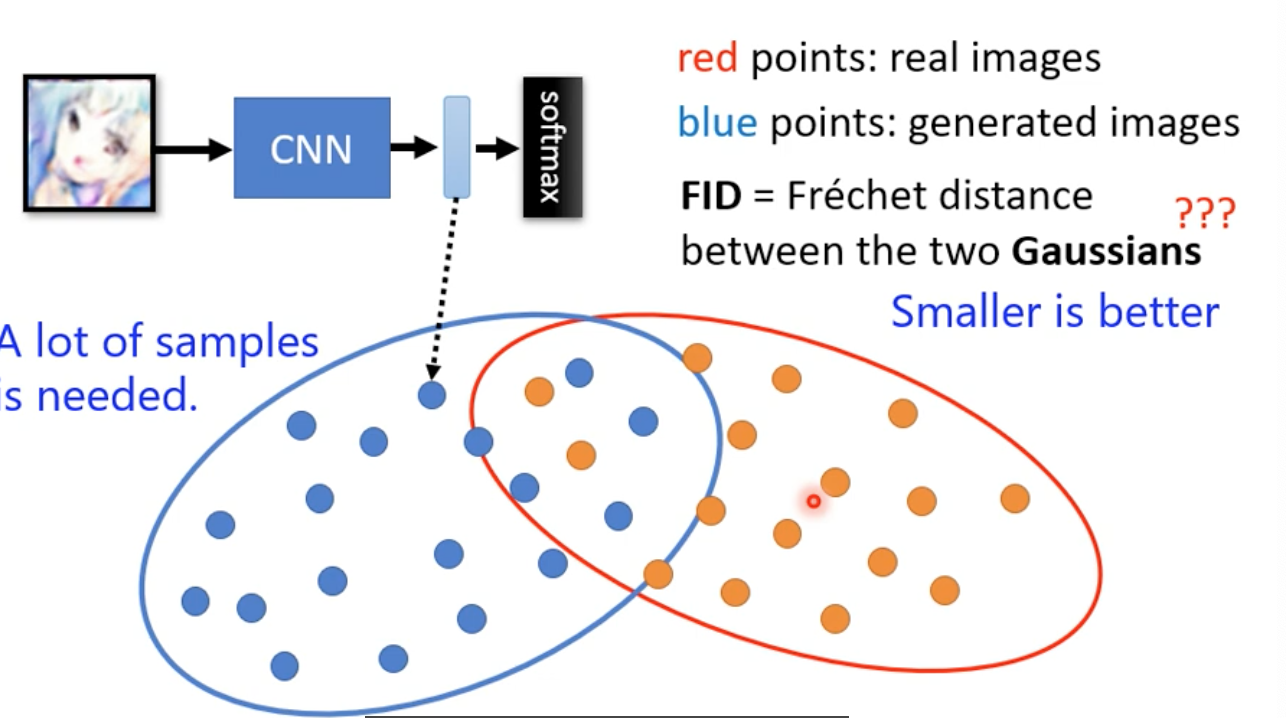
作業採用Frechet inception distance(FID)
- 把輸出丟入CNN,再把進入softmax前的那個vector拿出來作為輸入
- 假設真實圖片跟產生的圖片都是gaussian distribution
- 對他們算Frechet inception distance
- 越小品質越高
問題:需要很多samples,且不知道輸出分佈是否為gaussian
- 所以不能只看這個,作業會FID跟IS都參考
- 所以不能只看這個,作業會FID跟IS都參考
有時候,FID很好(低)而且人臉也做得很真實,也未必是一個很好的model
- memory GAN: 如果這個GAN可能是直接照抄訓練資料的,剛好符合diversity跟classification
- 可否比對訓練資料跟輸出的相似度?
- 也可能GAN剛好輸出都是輸入資料的左右反轉,相似度又比不出來
-> GAN的evaluation仍為可深入研究的題目
- 也可能GAN剛好輸出都是輸入資料的左右反轉,相似度又比不出來
Conditional Generation
到目前為止GAN都只講隨機的輸入
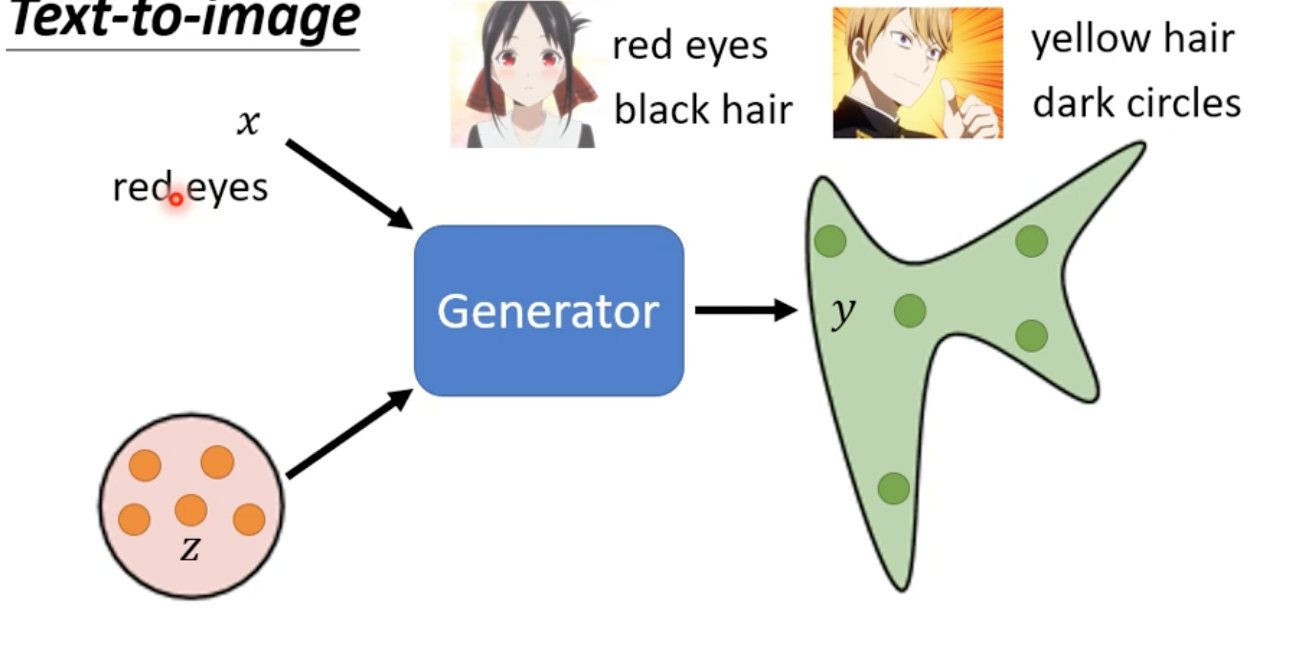
若給定一個x(條件),產生y
- Text to image任務
- Text to image任務
根據Sample的z不同,會產生滿足x條件的不同輸出
Discriminator
- 必須也知道文字敘述的條件,不然GAN只會產生清晰圖片,忽略條件
- Discriminator除了看圖片是否好,還要看是否吻合條件

text-image的training data通常會需要成對的資料(condition,image)
但是這樣通常訓練的結果不會很好
- 還是要mix一些label = 0(故意塞錯的) 的資料(清晰圖片+錯誤描述)
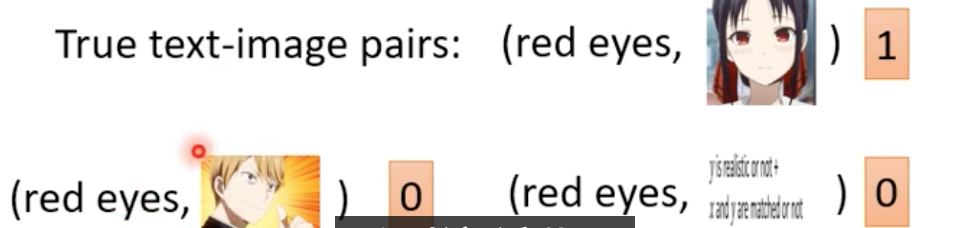
- 還是要mix一些label = 0(故意塞錯的) 的資料(清晰圖片+錯誤描述)
conditional GAN其他應用
sound to image
給聲音,然後畫出圖片
- 給sound一些label其實不難收集,可以爬影片然後get sound以及相關畫面
- (sound, “a dog barking sound”)
- (sound, “river sound”)

talking head generation
image to image
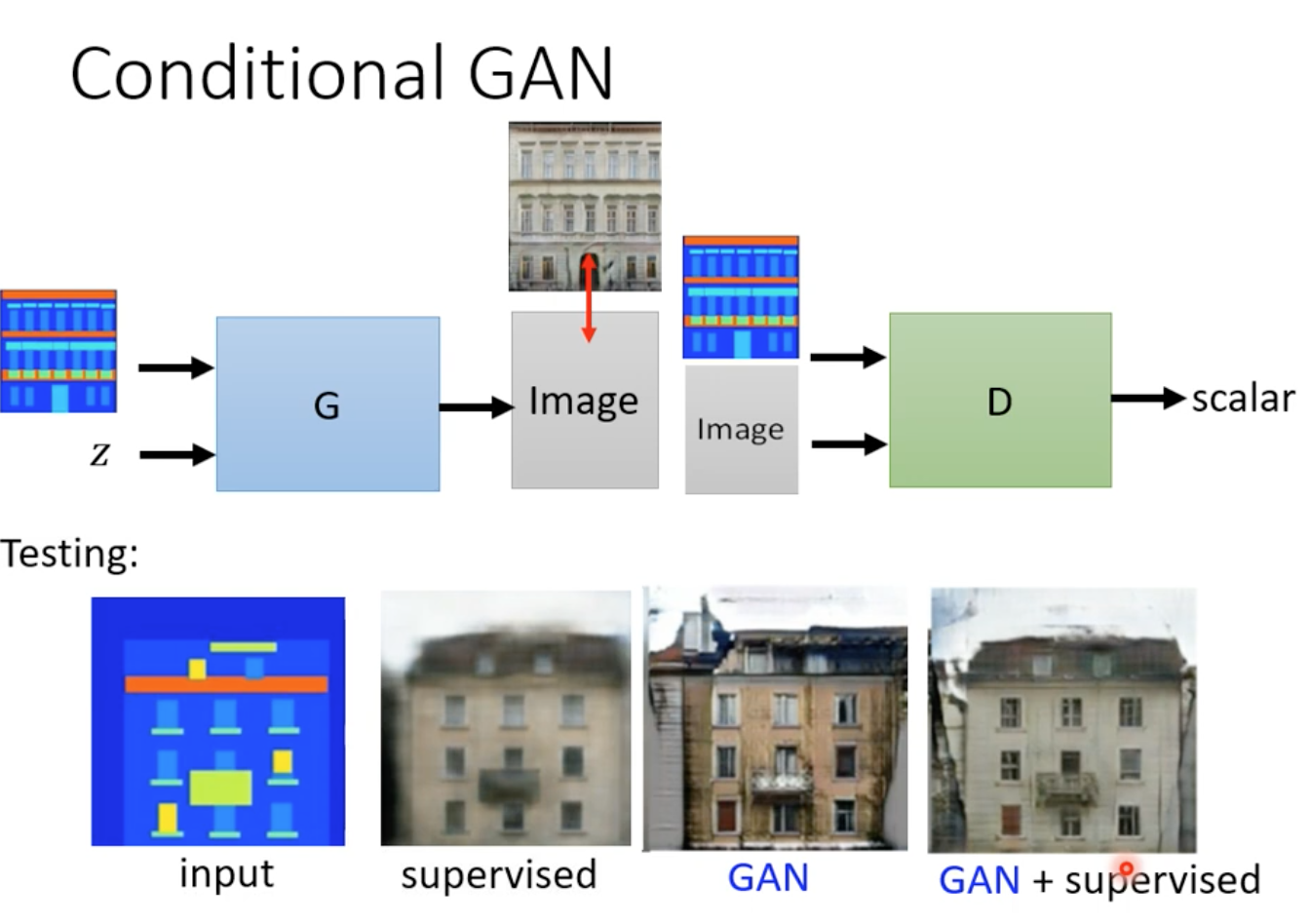
Conditional GAN也可以做image translation(輸入圖片,輸出吻合條件的圖片)
- pix2pix
老樣子,image 2 image用supervisied learning,可能會學習到類似的情況下,圖片輸入很多種,導致輸出模糊(同GAN一開始小精靈的例子)
- 所以還是要用GAN
- 但GAN可能還是會有想像力過度豐富的問題
- 兩者需要同時使用
- 所以還是要用GAN