ML_2021_X-1&X-2 BERT簡介
芝麻街家族與模型有很多關聯
BERT有340M個parameters,非常巨大
下面課程主要講BERT與GPT系列
BERT 就是transformer encoder
BERT learning technique
Semi-supervised?
- BERT用在下游任務需要labeled data做一些fine-tune,是supervised learning
- BERT pretrain過程卻不需要labeled data,是unsupervised learning
$\rightarrow$ 所以合起來稱為semi-supervised
Self-supervised?
- 雖然是supervised learning,但是卻不需要人工標記,這種方法將訓練資料本身作為label
- 我們會切割一部分的資料x’作為輸入,一部分的資料x’’則做為label
- 在沒有資料的情況下,自己想辦法supervised (故在人工方面可以看做是一種unsupervised)
- BERT的pretrain任務,就是self-supervised learning
Pretrain(Self-supervised learning)
- 不同於supervised,self-supervised的資料沒有標註,我們會切割一部分的資料x’作為輸入,一部分的資料x’’則做為label
- 在沒有資料的情況下,自己想辦法supervised (是一種unsupervised)
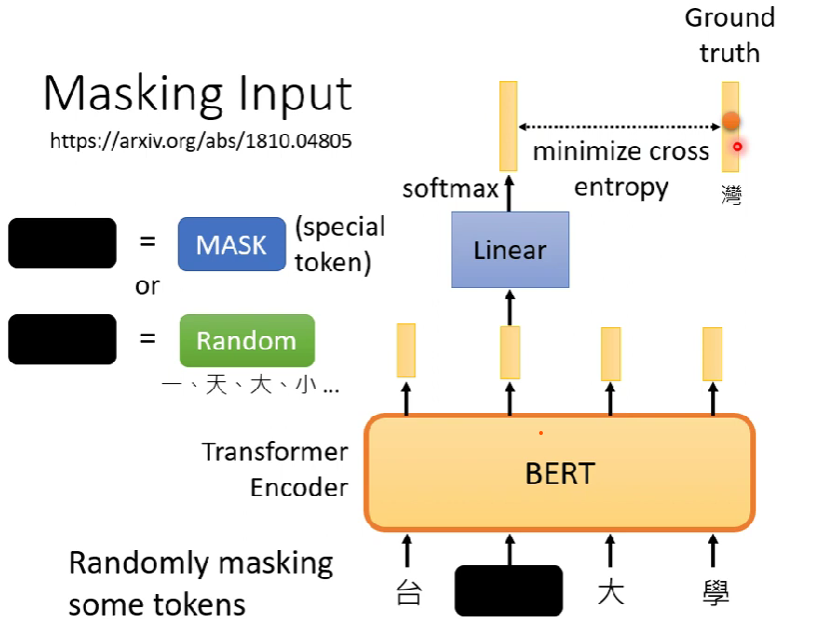
Pretrain任務1:masking input
- 會隨機把input sequence中隨機一個vector蓋掉,稱為masking input,然後讓BERT去訓練猜中原本蓋掉的詞(token)是甚麼
- mask / random
- 很像分類問題,類別量 = token總數
- BERT出來會有一個linear的matrix,做完softmax以後輸出
Pretrain任務2:Next sentence prediction
- 任取兩個sequence,在開頭跟句子之間加入分隔符號
- BERT要訓練去辨認這兩個例子是否相接
- 這招不是很有效,Robustly optimized BERT approach
- 一種可能是這個任務過於簡單
- 另外一招:sentence order prediction(SOP)
- 2句子本來就接在一起但亂序,要分辨誰是前面誰是後面
- 在ALBERT中使用
How to use BERT
- BERT雖然只做上述兩個訓練,但【卻可以使用在不同的任務上面 (downstream tasks)】
- 針對不同任務,BERT仍需要做一點微調(一些些的labeled data),稱為Fine-Tune
- 我們會讓BERT去做各種任務(任務集)取各種任務的成績以後平均
BERT 表現in GLUE
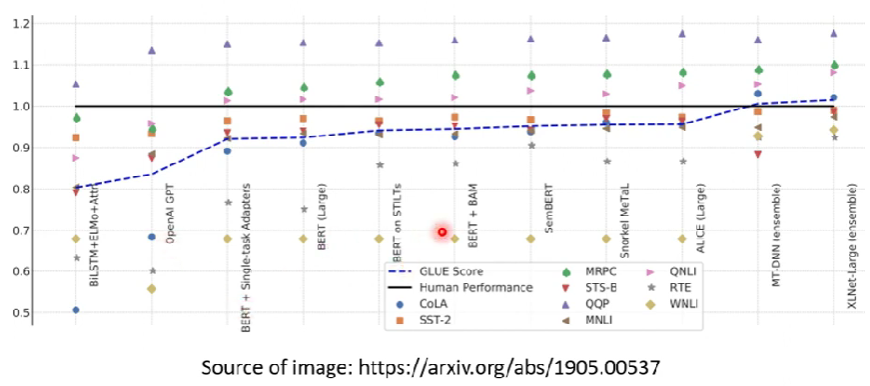
- 1.0的基準線是人類的成績(指標不一定是正確率)
BERT實務
Case 1
- 輸入一個sequence,輸出一個class (ex. sentiment analysis)
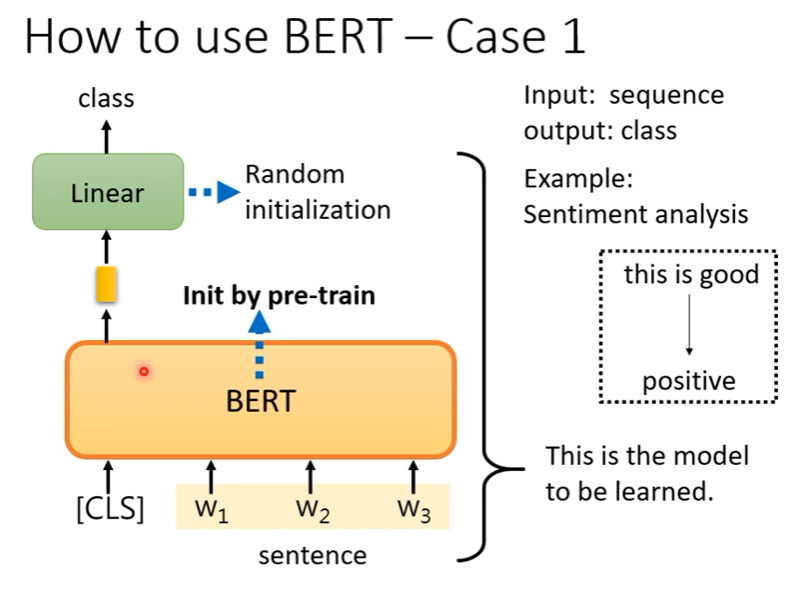
- 使用pretrained data後,BERT的參數已經被初始化了(一個會做填空題的BERT),而線性層則是仍然要隨機初始化
Case 2
輸入一個sequence,輸出一樣長度的sequence (詞性標註 POS tagging)
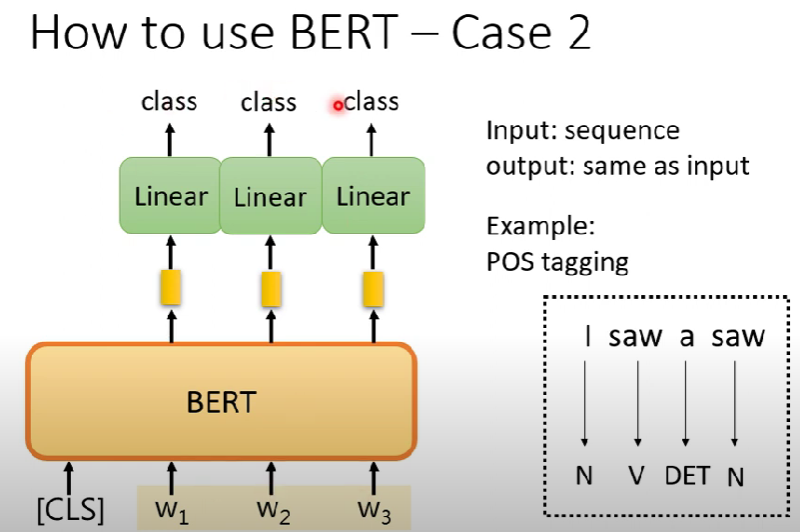
處理過程同case 1
Case 3
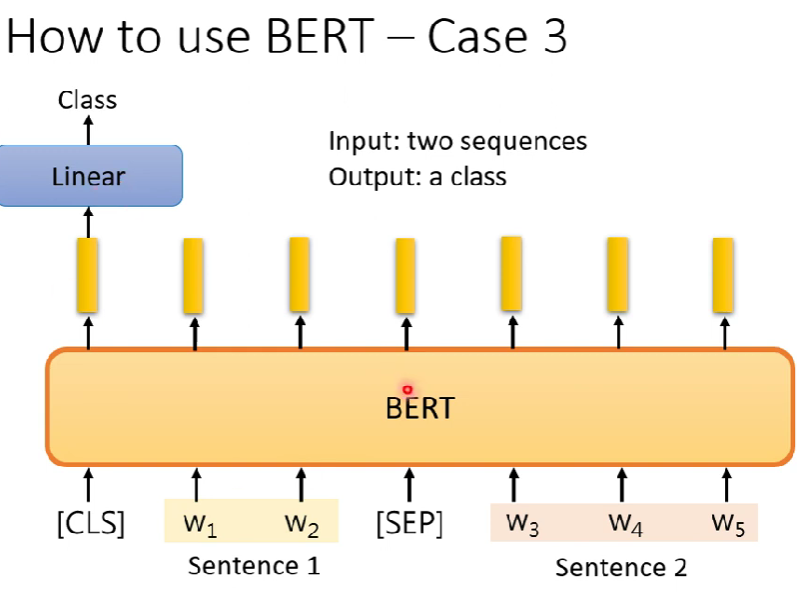
- 輸入兩個句子,輸出一個類別 (NLI)
- NLI : 從前提要能推出假設
Case 4 (作業7)
- 問答系統:給機器讀文章,問他問題要能回應
- 但是機器只能從文章中給出答案(抓取文章的特定序列)
- 輸出兩個正整數

輸入的形狀跟case 3很像,只是後面改成文章,前面改成問題
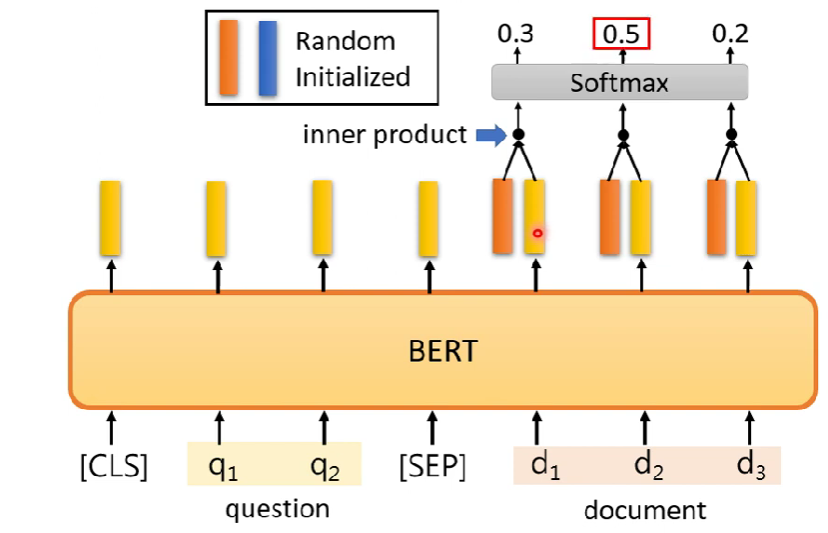
黃色向量輸出分別對橘、藍vector做內積,然後過softmax
答案會是($d_i,d_j)$,其中i來自橘色,j來自藍色
Training BERT is challenging
google訓練最早的BERT的時候用了3 billions words
訓練非常花時間,但是微調很快(colab GPU約1 hr)
既然BERT都已經被訓練過了,為何還會有人想要重新訓練他?
- 實際上訓練BERT的過程中,BERT到底學到了甚麼仍有待研究
- 為了學習BERT的胚胎學,所以會需要重新訓練
- 實際上訓練BERT的過程中,BERT到底學到了甚麼仍有待研究
如果今天要解的任務是seq2seq呢
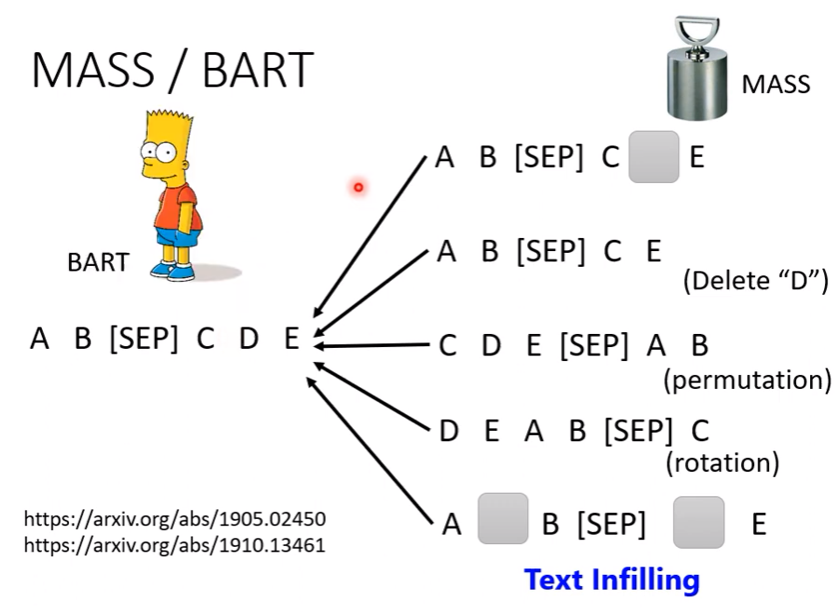
BERT只有pretrain encoder,有沒有辦法pretrain decoder? 可以。
Encoder看到corrupted的data,decoder則是要想辦法把他還原
- 弄壞資料的方法:旋轉、空白、mask…
- 弄壞資料的方法:旋轉、空白、mask…