ML_2021_X-3 BERT的奇聞軼事
明明只學填空,為何BERT有用?
you shall know a word by the company it keeps
詞向量並非是BERT為祖先
- BERT(contextualized word embedding) 、 CBOW(word embedding)
BERT會把各個詞彙變成一個詞向量,詞義越相近的詞彙,則他們的向量相似度會更像
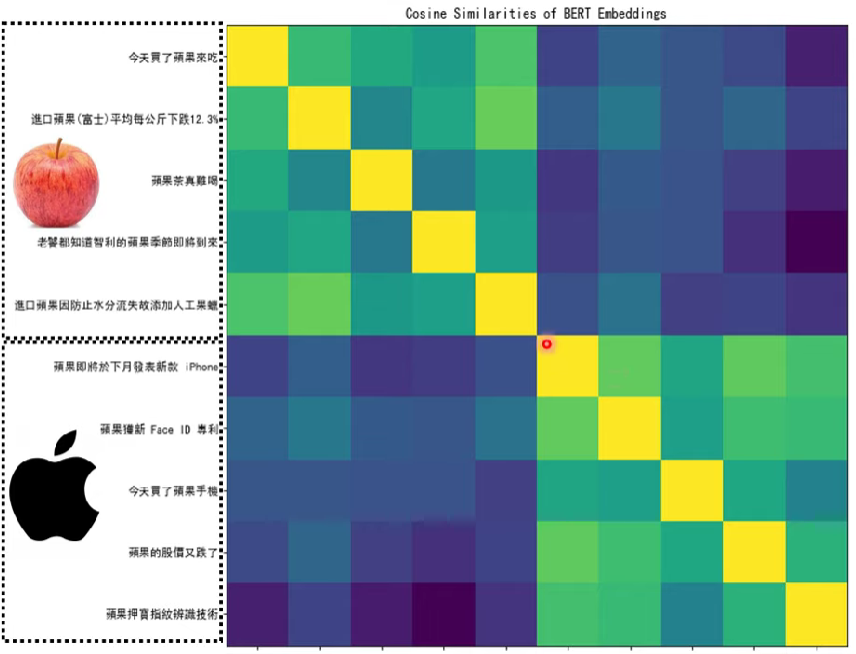
BERT是否真的看得懂文章?
基於語言學假設,知道詞彙的意思要看他的前後文
但BERT真的只拿詞彙的前後文當判別依據嗎?
- 拿BERT做DNA分類
把DNA序列(A,T,C,G)變成好幾個英文詞彙(隨機對)然後直接丟入BERT 做fine-tune training
- BERT pretrained by English
- ex. ATTACG -> He She She He It Us
出乎意料的用有pretrain的BERT命中率比直接用隨機參數的transformer encoder模型還高 (Reference)
- 這個實驗可以發現就算這整串文章毫無邏輯,BERT也可以表現的比完全隨機還好,表示機器就算看不懂文章,也學到了某些東西
- 關於BERT學習過程仍待研究
- 這個實驗可以發現就算這整串文章毫無邏輯,BERT也可以表現的比完全隨機還好,表示機器就算看不懂文章,也學到了某些東西
關於BERT的研究(變形)
Multi-lingual BERT
Train BERT with different languages
用多國語言訓練(pretrain)BERT,就可以解中文的資料集
- 相關論文實驗
- 多語言BERT模型的表現是最好的
或許對於不同語言之間差異不大? (仍有待研究)
- ex. 兔跟rabbit相近、游跟swim相近
老師的lab一開始也是嘗試train自己的multi-lingual BERT以查清BERT學習的方法
- 實驗結果顯示multi-lingual BERT需要的dataset很大
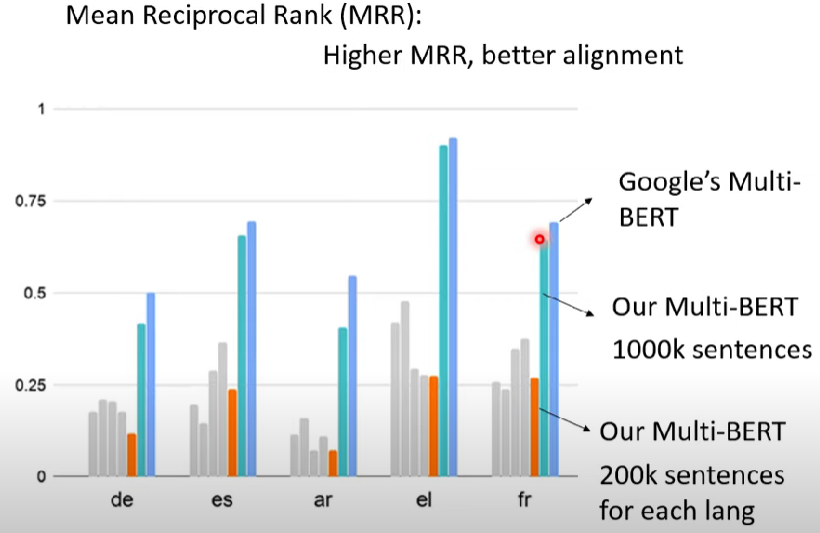
Reference
- 但是既然語言特性並非BERT的學習重點,為何不會輸入中文,吐出日文?
- 表示BERT還是會注意語言之間的差異
- 那如果抵銷掉語言之間的差異呢?
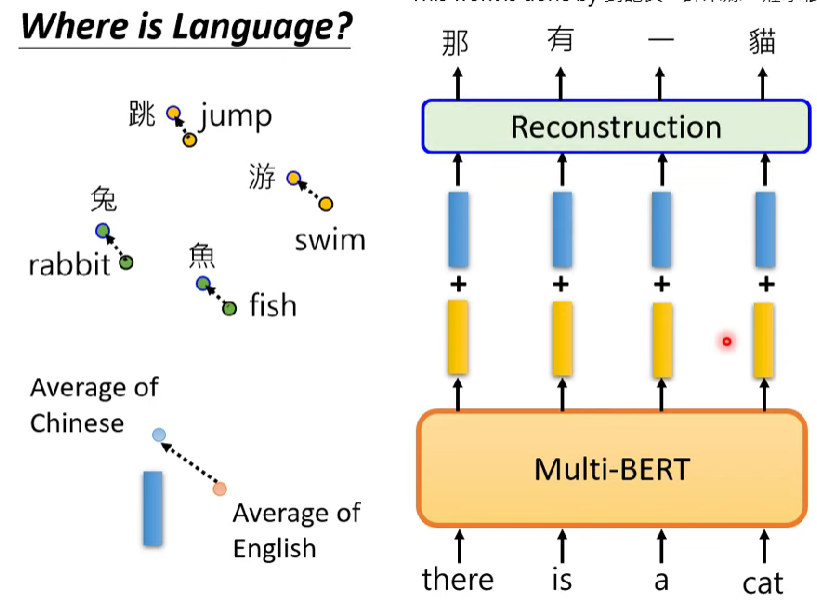
- 老師的lab實際把英文丟入BERT模型內,再加上一個向量,這個向量是英文與中文詞向量平均之間的差距,可以得出輸入英文,輸出中文的填空結果
