ML_LEE_2022_hw5
本次作業使用judgeboi
translate english to chinese
作業講解
datasets
- (en,zh-tw) paired data
Evaluation
- BLEU score
- 本次會需要對training data做一些preprocessing(norm,刪除極端資料)
技巧
- label smoothing
- tokenize
- lr scheduling (warm-up , 遞減lr)
- back translation (中英,英中都train)
- 不同語言的data需要保持在同一個維度
- backward model的表現很重要
- model capacity will increase,since data amount increased
- 不同語言的data需要保持在同一個維度
Baselines
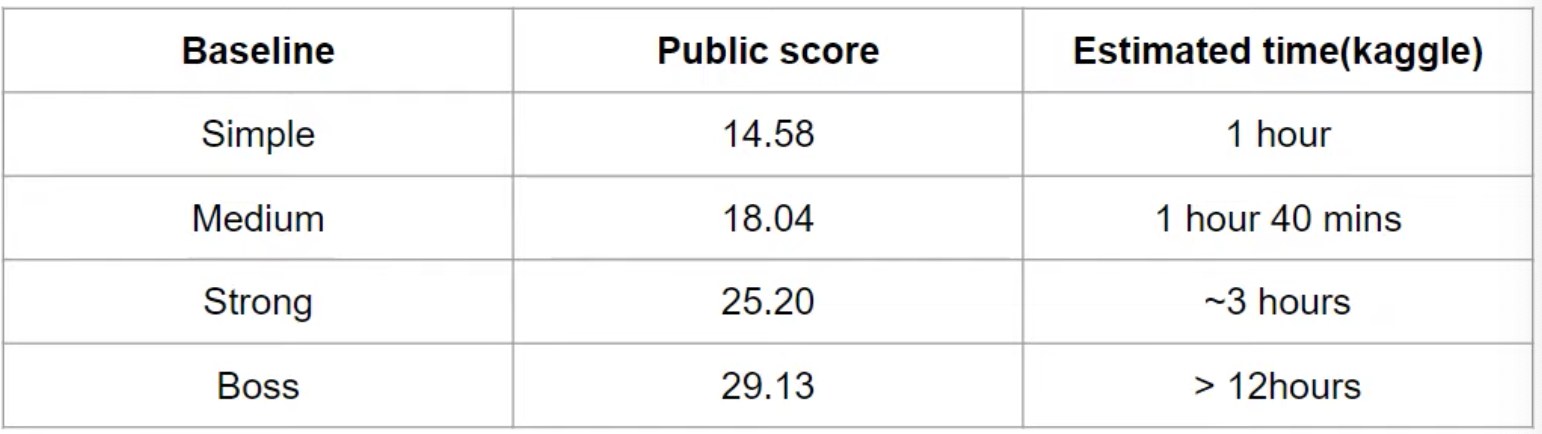
Simple: Train RNN seq2seq (Sample code)
Medium: add lr scheduler, train longer
Strong: 使用transformer, tuning hyperparameter
Boss: Apply back-translation
Note: 助教的ppt有建議hyperparameter
Report

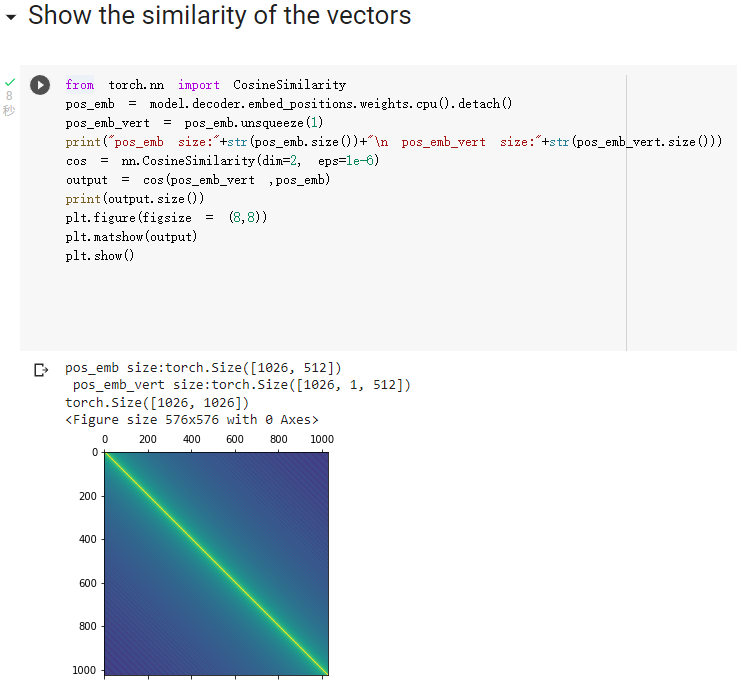
- 問題一:要visualize positional embedding,用一個2維matrix表示 (cosine similarity)
- 可以從decoder得到,使用
pos_emb = model.decoder.embed_positions.weights.cpu().detech()
- torch.size([1026,256]) (256維)
- 推薦使用cosine similarity
- 可以從decoder得到,使用
- 問題二:實作Clipping Gradient norm 並顯示出gradient norm
- 避免梯度爆炸
- Gradient norm: 把每個參數的gradient收集起來變成vector,對他們計算p-norm
- 作法:
1. 設定一個最大值max_norm
2. 收集paras,並計算他們的p-norm,命結果為Lnorm
3. 如果Lnorm > max_norm,則計算scale_factor = max_norm / Lnorm,並對每個gradient乘上scale_factor- 設定max_norm = 1.0
- Apply plot of “gradient norm v.s step”,並圈出Lnorm > max_norm的地方
- 助教的code已經有算出gnorm了,我們要把它儲存起來,才能在training結束的時候具現化它
寫作業歷程
這份作業無法繳交了,因為judgeboi已經關起來了qq,只能直接在本機用test data去驗證BLEU分數
觀察Sample Code
首先,來研究一下助教的code,整個notebook分為幾大片段:
下載資料集以及import packages
- 資料集來自fairseq
對資料集內容做前處理(clean_corpus)
- 移除一些垃圾字元
- 移除特殊符號
- 如果是中文,把全形轉換成半形
- 移除過長或過短的字詞
- min = 1
- max = 1000
- 輸出
train_dev.clean.zh/en
- 移除一些垃圾字元
切割valid/training set
- 1:99
- 輸出
train.clean.zh/en , valid.clean.zh/en4檔案
處理OOV問題
至此資料處理完成
模型定義
- fairseq?
- 預設RNN的encoder,decoder
- 大模型class由seq2seq包裝
實際instance長這樣:
1 | # HINT: TODO: switch to TransformerEncoder & TransformerDecoder |
所以要做的就是自己做一如下面的TransformerEncoder/Decoder,取代原本的RNN
助教強調對於seq2seq任務來說,init非常重要,下方的初始化會需要做出相對應的調整
Optimizer & learning rate schaduling
- lr這塊需要套公式,公式有給
至此模型初始化完成
Traing step
- 這裡沒什麼要注意的了
- 觀察一下要如何完成report
First Approach
直接run sample code,觀察運作方式
BLEU score = 16.08
1 | 2022-08-04 07:04:07 | INFO | hw5.seq2seq | BLEU = 16.08 43.4/21.3/11.4/6.3 (BP = 1.000 ratio = 1.009 hyp_len = 112803 ref_len = 111811) |
Second Approach
- 把encoder, decoder註解拿掉,由RNN改成Transformer
hyperparameter修正
- 參考attention is all you need的table 3

其中:
- $P_{drop}$ = Residual Drop
- $d_{ff/v/k/model}$ = dimension of fast-forward/key/value/model
- N = layer數
- $\epsilon_{ls}$ = label smoothing rate
我照著Base版修改hp
- encoder/decoder_embed_dim = 512
- encoder/decoder_ffn_embed_dim = 2048
- encoder/decoder_layers = 6
- args.encoder/decoder_attention_head = 8 (太高也不好)
修改learning rate 公式
lr = pow(d_model,-0.5)*min( pow(step_num,-0.5), step_num* pow(warmup_step,-1.5) )
Result
1 | 2022-08-04 16:04:59 | INFO | hw5.seq2seq | BLEU = 25.50 59.7/34.3/20.6/13.0 (BP = 0.937 ratio = 0.939 hyp_len = 105012 ref_len = 111811) |
有達到strong base line了,不過還沒做報告
Third Approach
之前沒有為完成report寫一些額外的code,這次把他補上了
Prob1:visualize positional embedding
參考了這篇網誌中的Report 1,自己做雖然有成功detach,但並不知道後續該怎麼做…對於CosineSimilarity與tensor dimention的掌握度不足..完全沒想到要用unsqueeze
Prob2:實作Clipping Gradient norm 並顯示出gradient norm
其實clipping gradient norm助教已經寫好了,我做的只是把每個step的gnorm存到一個list gnormList裡面,然後再把它丟進圖表裡面印出來
Mount google drive
有鑑於上次的大暴死,這次決定把epoch的cache保存在自己的雲端硬碟而非放在colab裡面
不然連線階段一個過期,整個檔案會被刪除,就算有save model都沒救…
Result
BLEU score = 25.63
1 | 2022-08-05 13:10:14 | INFO | hw5.seq2seq | example source: so we're hoping that's what they'll do . |
Report
Prolem 1
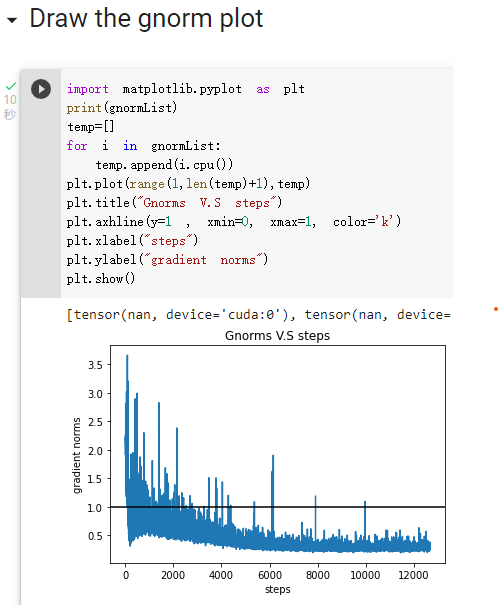
Problem 2
Reference
梯度爆炸
梯度爆炸:在error surface平坦的地方,設的lr過大,導致整個參數大跑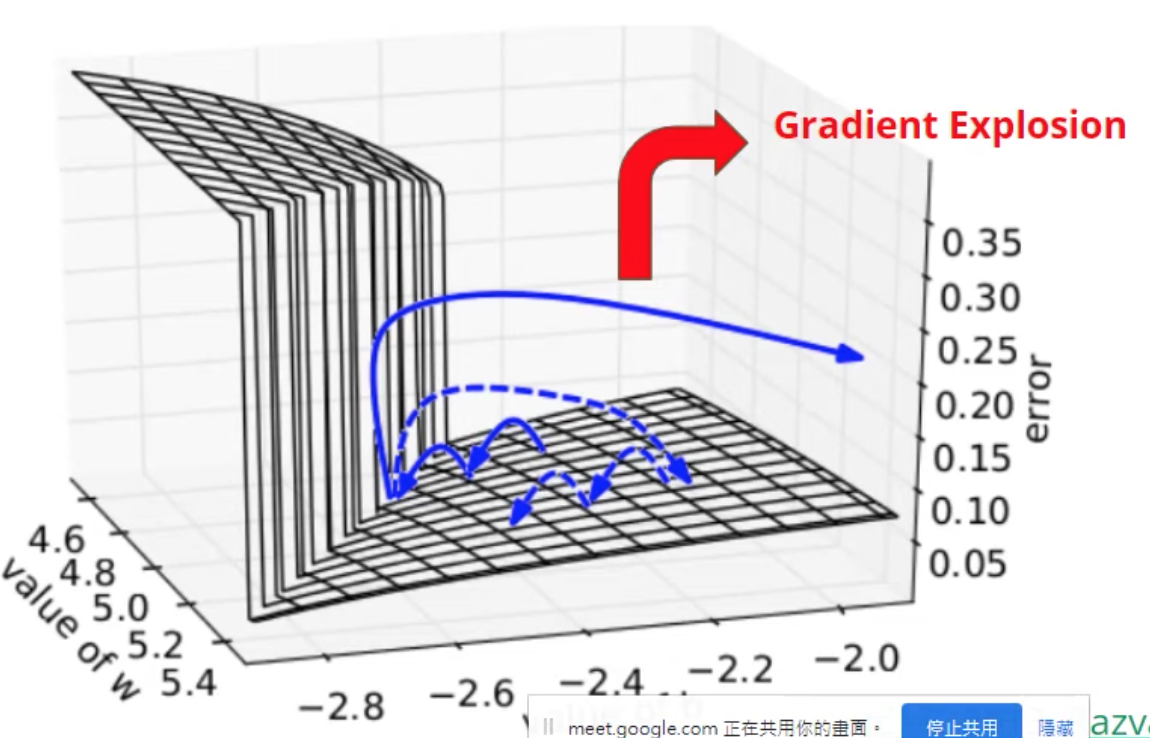
OOV (out of vacabulary)
- 類似人類會的英語字彙不足,不足以表達意涵
- 字彙過長,不好處理
- 本作業中使用subwords來解決這個問題,Reference
Google雲端
本次作業的模型參數檔、gnorm軌跡與預測結果連結