ML_2021_8-1 基本概念
也不用label data就可以做pretrain -> 算是一種self-supervised learning
出現在2006年,是很老的模型
Auto-encoder 模型
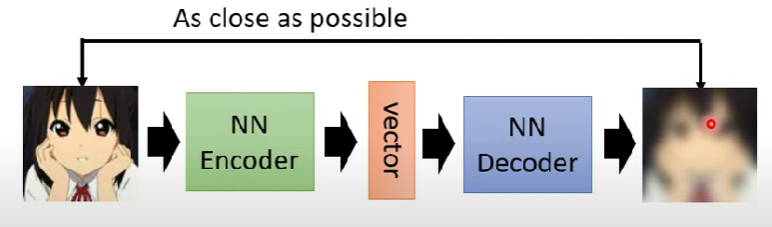
Auto-encoder也有encoder、decoder的兩層network,輸入會是一張unlabeled的圖片,經過encoder以後變成向量,再透過decoder變回一張圖片
訓練的目標是希望decoder輸出的圖與原圖越像越好(距離越近越好)
- 又稱為reconstruction
很像Cycle GAN中,2個generator之間的關係
關於中間的vector,有很多別稱
- Embedding, Representation, Code
auto-encoder的encoder通常輸入是為度很高的向量,而中介的vector則是維度低很多的向量,故可用於壓縮
- 具備壓縮的功能
- encoder的輸出也叫做bottleneck
- 這樣降維的技術稱為「dimention reduction」
- 具備壓縮的功能
Why auto-encoder
- 為何有辦法讓低維度向量變成一個圖片呢?
- 圖片的變化有限,把變化的可能性記下來,就可以把一個複雜的圖片用簡單的方式記錄下來
變形:De-noising auto-encode
也不是多新的技術(2008)
把輸入的圖片先隨便加入一些雜訊,但是要decoder還原加入雜訊之前的結果
- auto-encoder必須自己學會把雜訊去除
這個idea其實跟現今的BERT很像(填空)
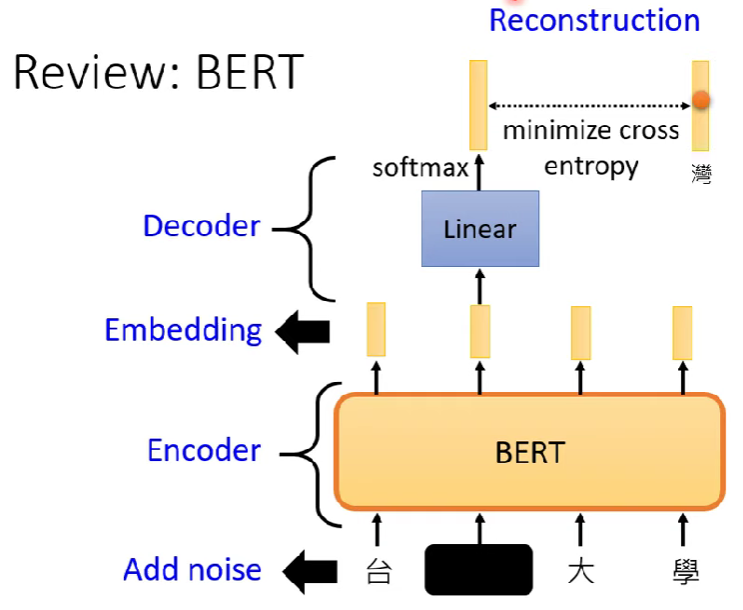
- BERT又可看作一個de-noising auto-encoder
- BERT的decoder不一定是linear。 廣義來看,可以把BERT切開,比如一個BERT前6層是encoder,後6層+linear layer是decoder