ML_2021_9-1 為什麼類神經網路可以正確分辨寶可夢和數碼寶貝呢?
Correct answers != Intelligent
Why we need explainable ML
- 對現實決策的解釋性
如果銀行利用機器學習來做是否貸款的判斷,則法律規定機器學習必須給出拒絕/同意貸款的理由
醫療、法律、自駕車、金融等等領域,不滿足於機器學習的黑箱
- 可以更好的去調整Model
Interpretable v.s Powerful
Linear model能力差,但是他容易解釋
Deep networks雖然強大,卻無法被解釋
與其侷限只用linear model,不如學著讓深度模型可以被解釋
- How about decision tree?
- Decision tree can be terrible
- 通常會用的都是random forest,而非單一一棵decision tree
- Decision tree can be terrible
Goal of Explainable ML
- 判准不好定義,以下是老師個人界定
人腦也是黑盒子,但我們卻可以相信人的決斷
相關心理學實驗:印表機
很多時候人們只是想要一個可以說服他們的理由,所以所謂的Explainable ML其實就是模型的決斷可以給出一個說服老闆、客戶、你自己的一種理由
Explainable ML的兩大類
問在甚麼情況下會這樣分類 (“你覺得貓看起來像如何”)
- Local explanation
- Global explanation
Local explanation
根據一個圖片(data)來問問題 (“為何圖片是一隻貓”)
- 要找出一個data的哪個component對於機器的分類至關重要
- 一種做法是:遮蓋資料的不同部分,看是否會影響機器的預測結果
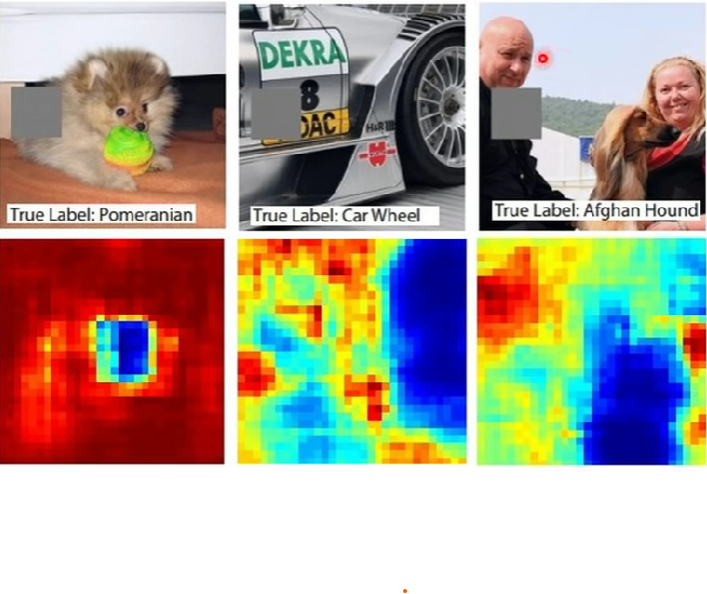
- 一種做法是:遮蓋資料的不同部分,看是否會影響機器的預測結果
另一種作法:Saliency map
針對各維的weight,加上$\Delta x$,看這樣損失函數值e的變化量為何 (|$\frac{\Delta e}{\Delta x}$|)
(其實就是|$\frac{\partial e}{\partial x_n}$|)
以圖片為例,可以得出下圖結果,此圖稱為saliency map(像素越白表示重要性越高)
但是Saliency也有限制,會碰到的問題與解決方式如下:
- Noisy Gradient:資料的判別依據混入了雜訊 -> SmoothGrad
- Gradient Saturation:可能一張圖片的特徵已經足以明顯,再對這個明顯的特徵做偏微分以後,e的變化性依然不大,則可能會誤判這個特徵點不重要 -> 有替代的做法稱為「Integrated gradient(IG)」,相關文獻:https://arxiv.org/abs/1611.02639
ex: 大象鼻子長度作為判別是否為大象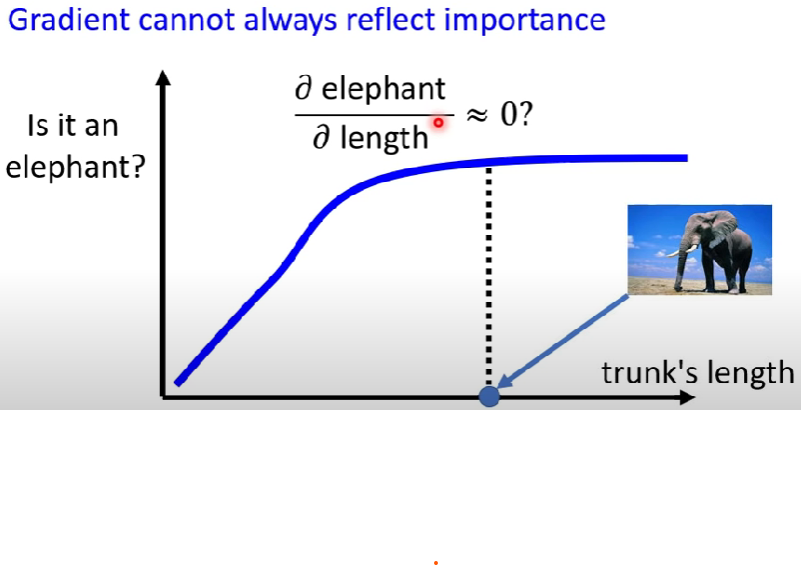
SmoothGrad
這個技術就是把原始的圖片輸入隨機加入一些雜訊並分別計算他們的Saliency map再取平均,真正重要的部位就會被凸顯出來
機器如何處理輸入
前面主要都在說機器如何找出一個輸入的重要部分
現在要探討的則是機器如何去處理這個輸入的
Visualization:具現化用肉眼觀察
- 直接去看neuron、attention的輸出是甚麼。雖然輸出的維度很高,但是可以透過一些方法(PCA、t-SNE等等)壓縮成二維並顯示出來
以作業2為例解釋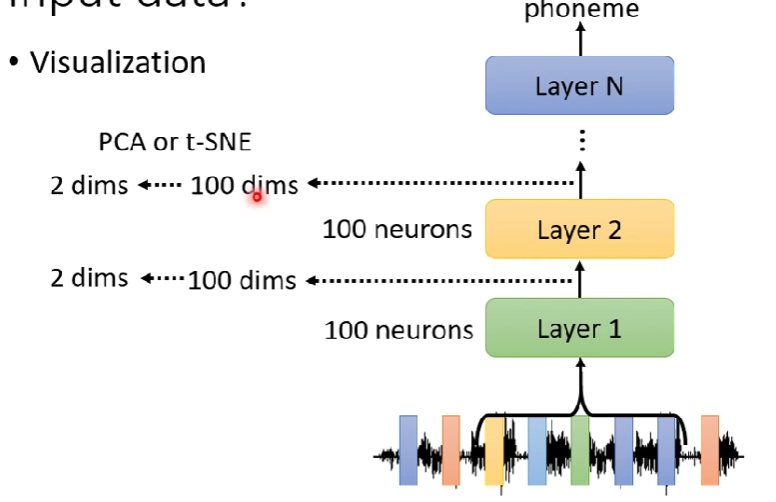
透過觀察被壓縮後的結果,我們可以看出一些特性
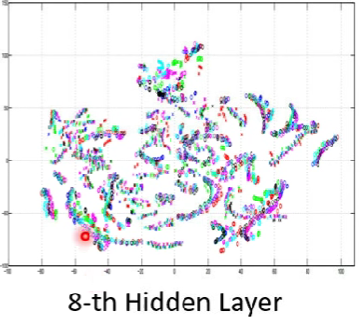
比如範例中的model某層輸出,可以看出機器可以看的出不同人所說的同樣內容,並把他們align在一起
關於attention可否被解釋,有諸多論戰
Probing:用探針插入network來觀察發生甚麼事
訓練一個classifier,將embedding丟進去,讓classifier試圖去訓練是否可以分類出想要的資訊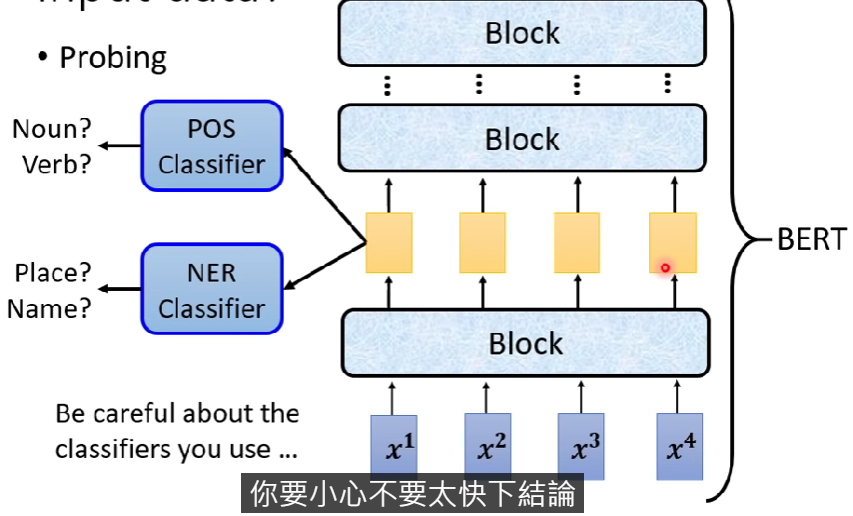
注意,probing仍會失誤,不可太快下定論(ex. 分類模型練壞等等)
- 一種probing應用的範例:
用作業二(語者辨識)的範例,可以把特定layer的輸出embedding丟入TTS模型,讓TTS模型想辦法還原原始的輸入。
若TTS無法完整的還原某塊部分(如.語者資訊),則可以知道這個network有學到抹去語者的資訊,只保留語音內容。
另一個probing例子
- 是李老師的論文
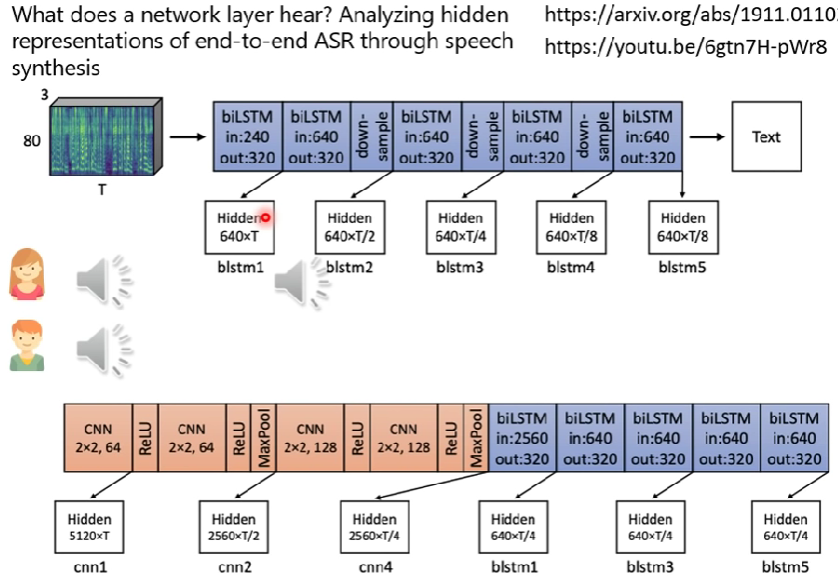
- 論文連結