ML_2021_10-2 類神經網路能否躲過人類深不見底的惡意?
在前面的攻擊,是假設我們知道模型的weights,這類攻擊稱為White box attack
白箱攻擊非常簡單,盡量不要暴露parameters
下面課程前半部以圖片辨識為例介紹
Black box attack
1. Proxy network
a. 原理
我們雖然不知道想攻擊的模型的參數,但我們可以透過用同樣一批訓練資料,練出一個自己的網路。當我們能透過白箱攻擊讓Proxy network出現漏洞,則我們也有可能可以用同樣的方式讓想攻擊的network淪陷
b. 若無訓練資料
如果沒有訓練資料,也可以透過自己準備一批資料,餵給想攻擊的模型,讓他吐出一堆輸出,把輸入與輸出綁成成對資料,再拿去訓練自己的proxy network

c. Advanced technique: Ensemble attack
- 透過使用Ensemble model有效提高攻擊的強度
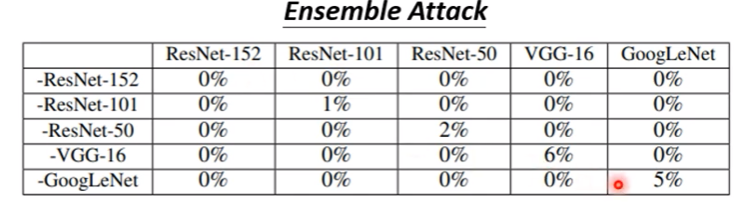
上圖縱列是指拿掉甚麼network,橫列則是被攻擊的network,如「-ResNet-152」那列就是結合除了ResNet-152以外的4個network所訓練出來的proxy network對各網路的攻擊結果;其中非對角線部分因為已在proxy network被訓練過,均視為白箱攻擊,不計入(0%)
為何黑箱攻擊如此容易成功?
- 至今仍然還沒有確定性的答案
- 多數人相信是因為模型之間存在著相似性,如下圖

圖片為一個高維向量,圖片的值是為原點,圖片的橫軸為可以讓攻擊成功的維度變化量,縱軸則為其他維度的偏移量。
可以發現,能在VGG-16攻擊成功的維度偏移方向,與其餘4種network均很相近。也就是說,能找到在VGG-16攻擊成功的圖片偏移方向與大小,在其他network上均大同小異。
目前有一群人認為:或許Adversarial attack會成功,不是因為模型的問題,而是資料本身的特徵真的就是長那樣 $\rightarrow$ 或許資料量更大就能避免
One pixel attack
只動圖片裡的1 pixel就達成攻擊目的
- 來源論文
- 目前效果有限
Universal Adversarial Attack
- 針對一個network的全方位攻擊方式
針對不同的圖片輸入,客製化出一個攻擊方式
Adversarial reprogramming
有點像殭屍寄生,讓原本的model輸出非他原本訓練想要的結果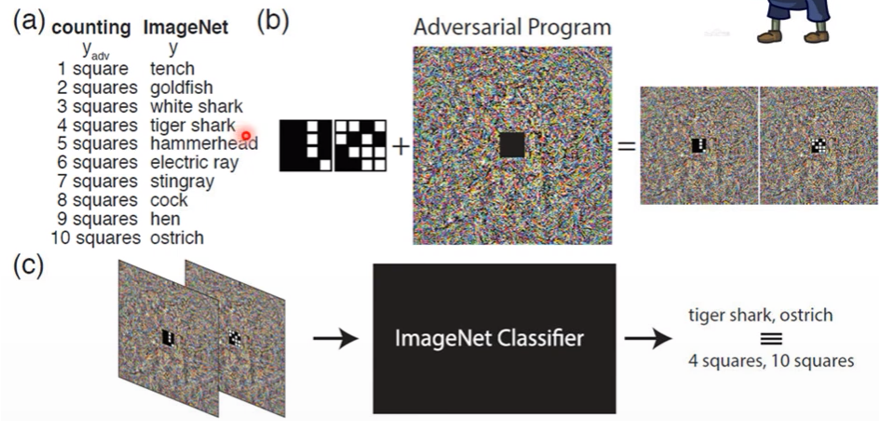
Backdoor in model
- 在訓練階段就展開攻擊
- 來源論文
- 在訓練資料就放入attacked image,讓模型練完以後看似正常,卻只對單一類型圖片會出現問題,如同後門
$rightarrow$ 若這樣的技術成熟,公開資料集將會變得不安全
其他領域的攻擊應用
1. Speech processing
- Detect synthesized speech:抓出合成的聲音訊號
攻擊者刻意在合成音裡面加入雜訊,讓機器以為那是原聲
2. NLP
文字輸入,進行機器QA
刻意在文字中加入雜訊,讓機器搞錯重點
3. 人臉辨識:真實世界攻擊
- 既然能在虛擬世界中對圖片加工造成機器判別錯誤,當然也有可能在現實世界中對人臉加裝配件對機器造成攻擊

- 現實世界需要考慮諸多因素
- 攝影角度 $\rightarrow$ universal attack(?
- 解析度問題
- 眼鏡印製的色差問題
- 攝影角度 $\rightarrow$ universal attack(?
除此以外,也有針對交通號誌的攻擊,讓自駕車變得困難
Defence
- 防禦分為兩種
- 主動防禦
- 被動防禦
1. 被動防禦
network不動,在圖片丟入之前放一個Filter,來隔絕雜訊
一種簡單的做法是刻意把圖片模糊化,讓原本可以讓攻擊成功的維度偏移量改變
- 但同時也會降低原始正常圖片的辨識度
a. 更多作法
圖片壓縮(刻意失真)
讓Generator重新把input image重新畫一遍
- 是有方法讓Generator產生一樣東西的,但因為generator沒看過雜訊,會產生不出來
- 相關文獻
- 是有方法讓Generator產生一樣東西的,但因為generator沒看過雜訊,會產生不出來
被動防禦(模糊化)也可以視為在network前面加入一層,所以一旦被知道以後,防禦力將會大減 $\rightarrow$ 隨機化
b. Randomization
- 把圖片隨機resize,padded一些背景之後再丟入network
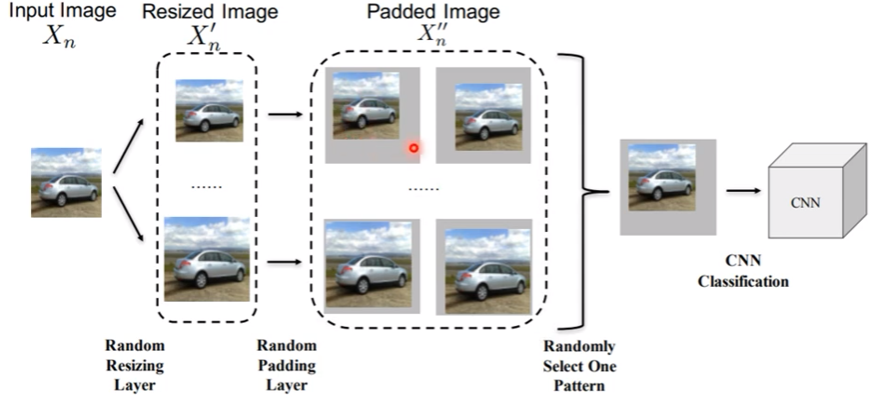
仍然有可能被攻破,抓出所有可能以後用universal attack
2. 主動防禦
a. Adversarial training
在訓練階段就讓模型被攻擊
把原始圖片做成attacked image後標上正確label以後再丟入model
某種程度上就是data augmentation (有洞就補洞)
- 就算不會被攻擊,也會有人用這樣的方式來強化model(降低overfitting可能性)
訓練過程需要大量訓練資源,且如果碰到沒補過洞的attack algorithm,依然會被攻破
有方法是不需額外計算的情況下做到adversarial training