ML_2021_11-1 概述領域自適應
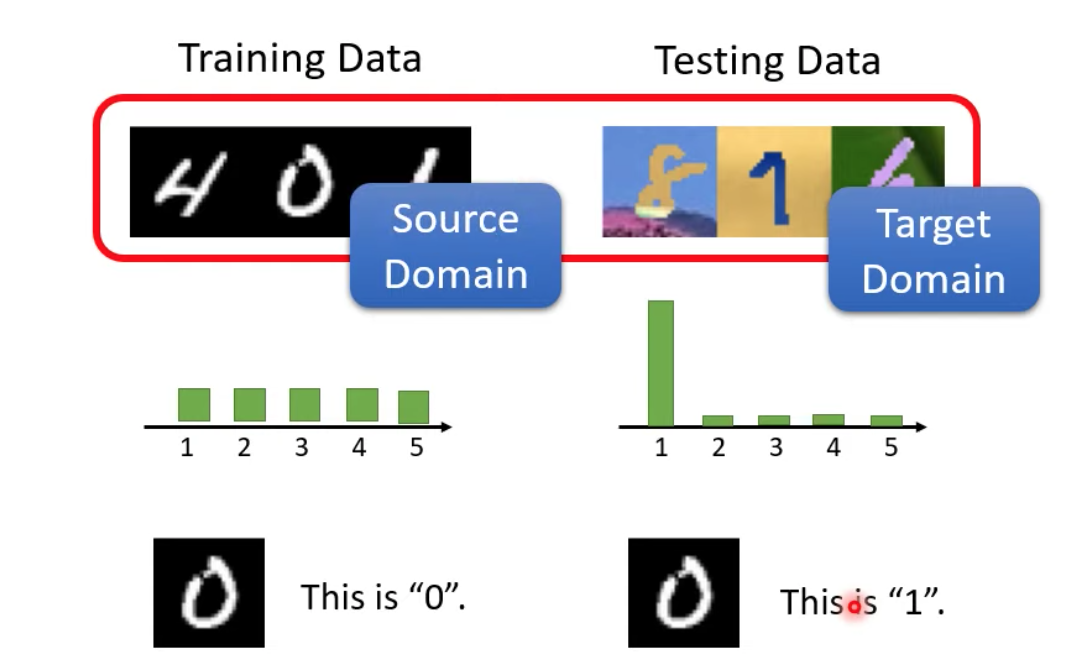
Train跟testing data之間可能會有不同的分佈 -> domain shift
ex. 用黑白圖片訓練數字辨識,但測試資料使用彩色圖片,則命中率會大幅降低
Domain shift的種類
- 不只是輸入資料的特性不合
- 可能輸出的資料,其機率分佈不一樣
- 或是也許在測試資料裡面,雖然圖樣跟訓練資料很像,但是它所代表的意涵卻不一樣
Domain adaptation
- 可以看作是transfer learning的一種
- 我們會需要對target domain有一些了解
Case 1:有target domain的labeled資料但資料量很少
- 用類似BERT的fine-tune方法來微調一下model
- 但target domain資料量很少,所以很容易overfitting
- 限制fine-tune前後的參數變化量
- 降低lr
- 限制epoch數
- 限制fine-tune前後的參數變化量
Case 2:有一大堆target domain的unlabeled資料
- 本課的討論重點
- 在實務上比較有常發生
- Idea:用一個feature extractor把source跟target domain的不同點刪除,擷取出共同的部分
- Ex.數字辨識,學習去忽略圖片顏色
Domain Adversarial training
原理
我們會訓練出一個new image classifier model,其中前半部分是feature extractor,後半部則是label predictor
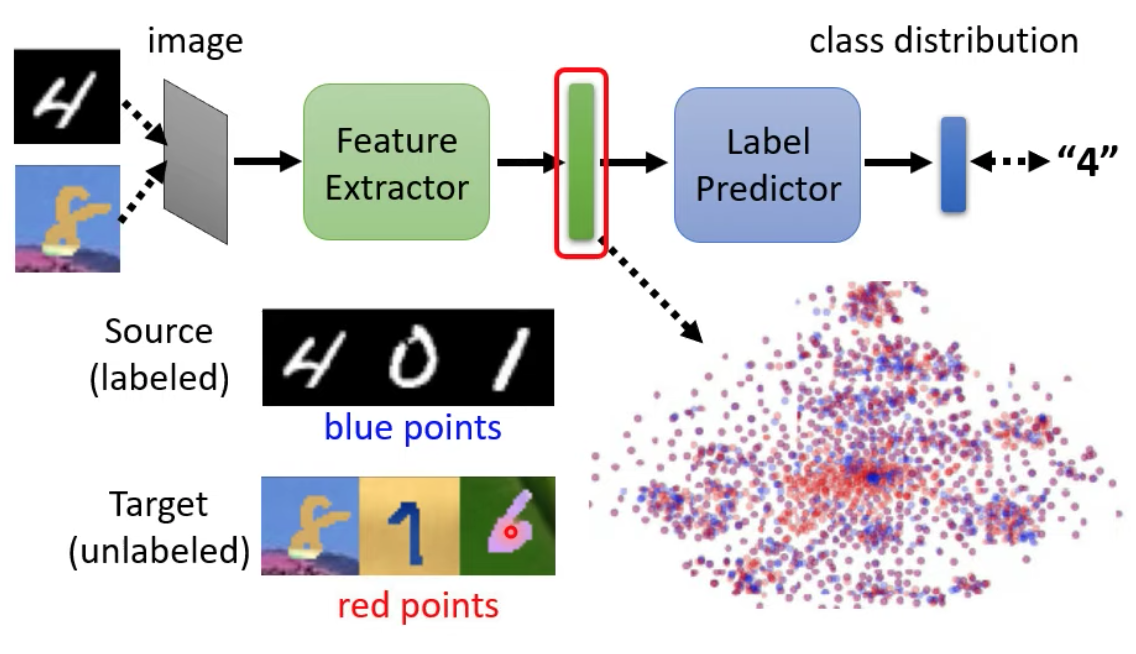
我們會希望feature extractor的輸出(上圖右下角的分佈圖),source跟target domain的分佈看不出差異
由feature extractor跟domain classifier互相對抗,將feature extractor的輸出送到domain classifier,domain classifier要想辦法辨認出這個輸出是來自source還是target domain
feature extractor -> Generator & domain classifier -> Discriminator
但這樣對於feature extractor優勢太大,因為只要他都輸出0,就可以讓domain classifier被輕鬆騙過去 -> 讓label Predictor也加入戰局
計算方法
令
- Feature extractor的參數為$\theta_f$
- Label Predictor的參數為$\theta_p$
- Domain Classifier的參數為$\theta_d$
- 輸出圖片預測結果與真實結果的loss(cross entropy)為$L$
- Domain Classifier二元分類器的輸出loss為$L_d$
因為我們同時希望Label Predictor分類越正確越好,又同時希望domain classifier能被騙過。則可以得出一個最佳化feature extractor的公式(非正確,勿照抄)
$$
\theta_f^* = min_{\theta_f}\ L-L_d
$$
問題來了,如果我們直接套用這個公式,會導致$L_d$越大越好(也就是讓domain classifier的loss飆高),這可能讓feature extractor變成努力讓domain classifier把target看成source,source看成target,而這也是某種程度上的分隔開兩個domain
如何改善公式,留給大家思考orz
domain adversarial training的效果拔群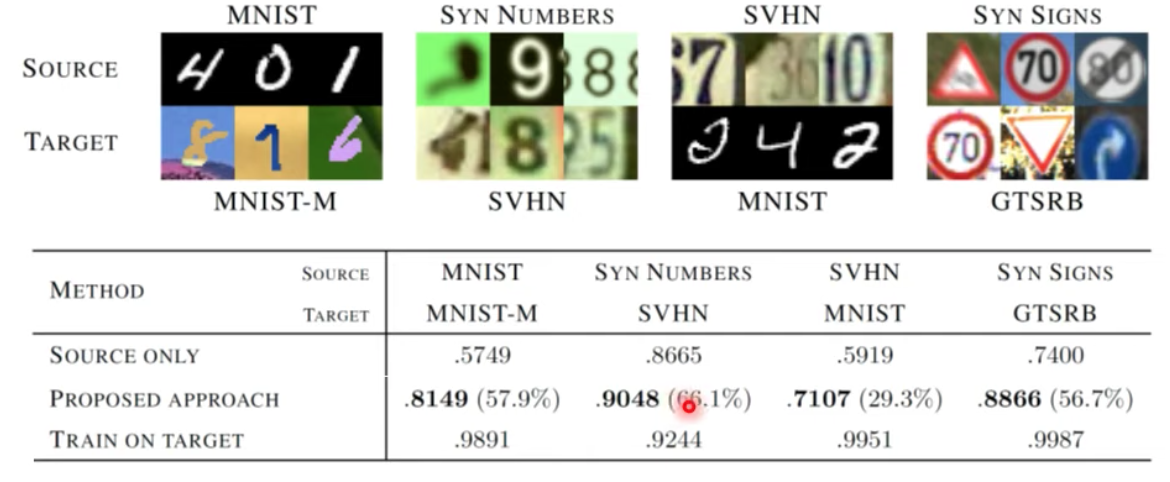
Limitation
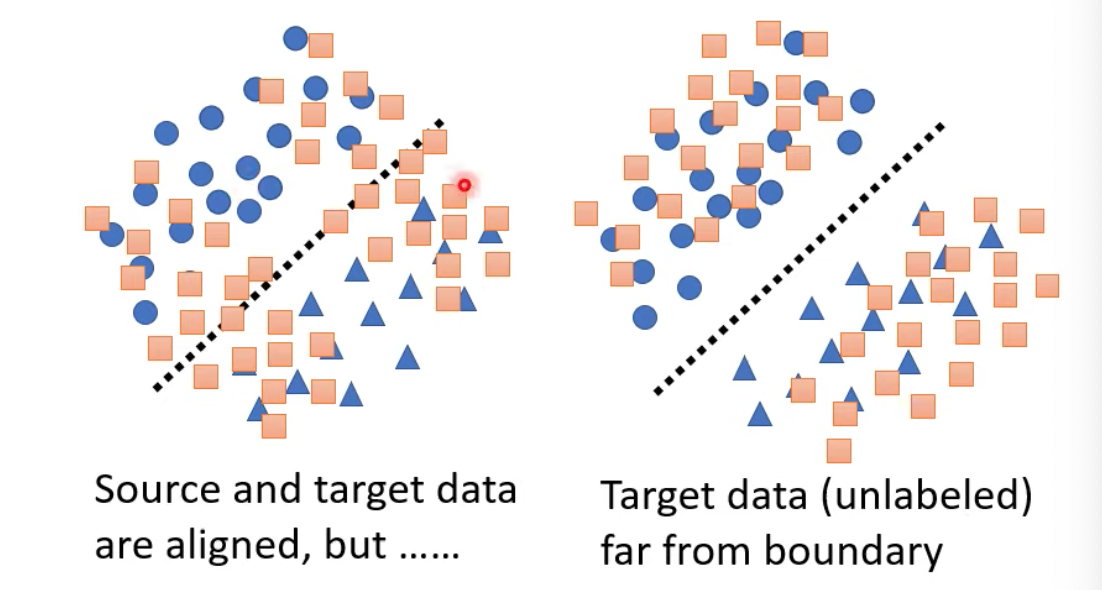
由上面的公式,我們可以練出上圖兩種類型的model滿足上面的公式,但是可以明顯看出,右邊的分佈會比左邊還好
我們雖然不知道橘色(target domain)的label為何,但我們知道藍色(source)資料的分界線,因此我們要在這樣的前提下,想辦法也讓橘色的資料被該分界線劃清
- 有很多相關方法
- 參考文獻:DIRT-T
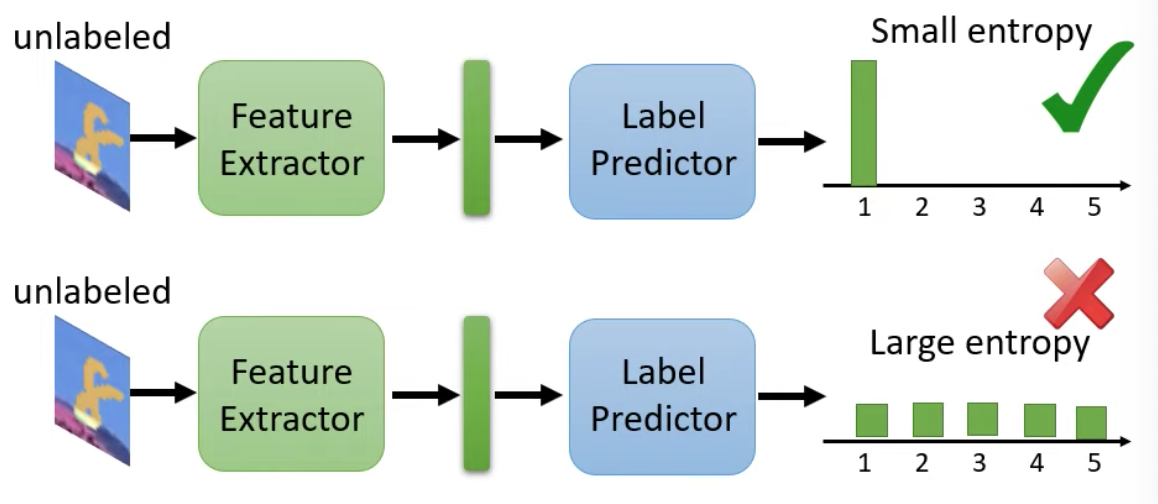
- 一種簡單的方向是確保unlabeled data丟入label predictor後輸出的分佈越集中越好
Case 3:雖然Target domain unlabeled data很多,但Source跟Target domain的class集合不同
到目前為止,我們都假設target跟source domain的類別集合是一樣的
如果類別集合不同,則硬要align data可能會反導致兩個無關的class被綁在一起 $\rightarrow$ Universal domain adaptation