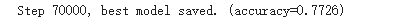作業題目
可進行的目標
Medium : 0.70375 (train 1~1.5 hr)
Strong : 0.77750 (train 3~4 hr)
Boss : 0.86500 (train 2~2.5 hr )
包括降低multi-head數量、feedforward dropout rate等等
降低pred-layer的linear connect layer層數 (這個問題複雜度不高,線性聯階層不用到兩層)
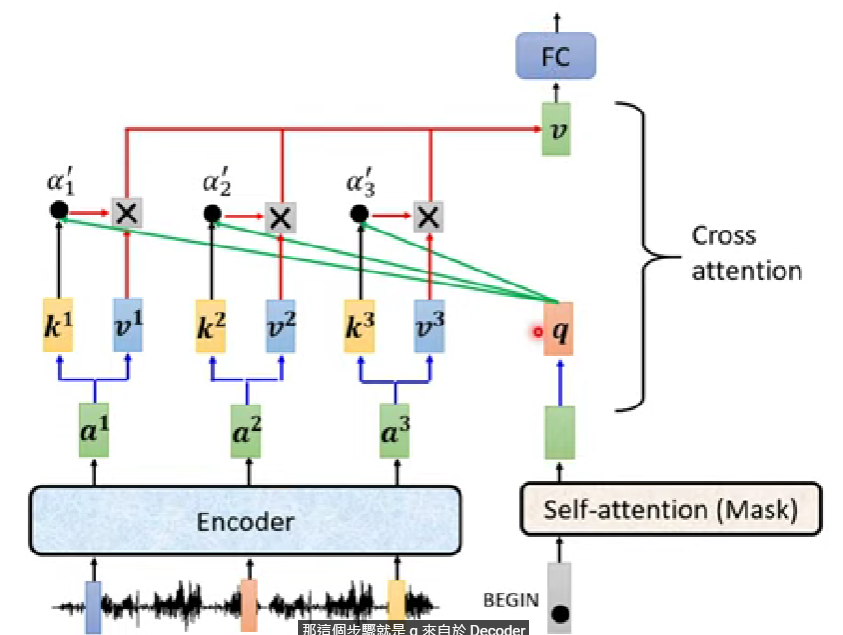
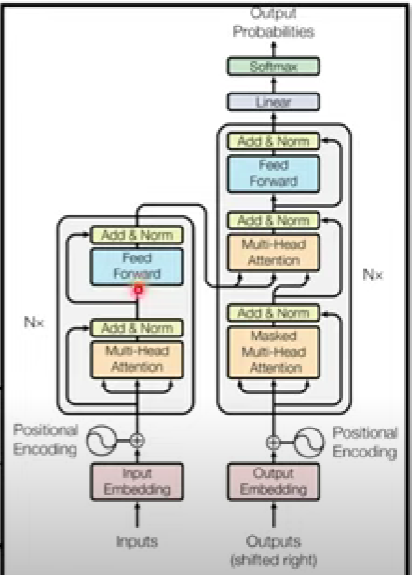
把原本的 self.encoder_layer改掉,套用conformer模型
conformer來源 記得修改Classifier的forward
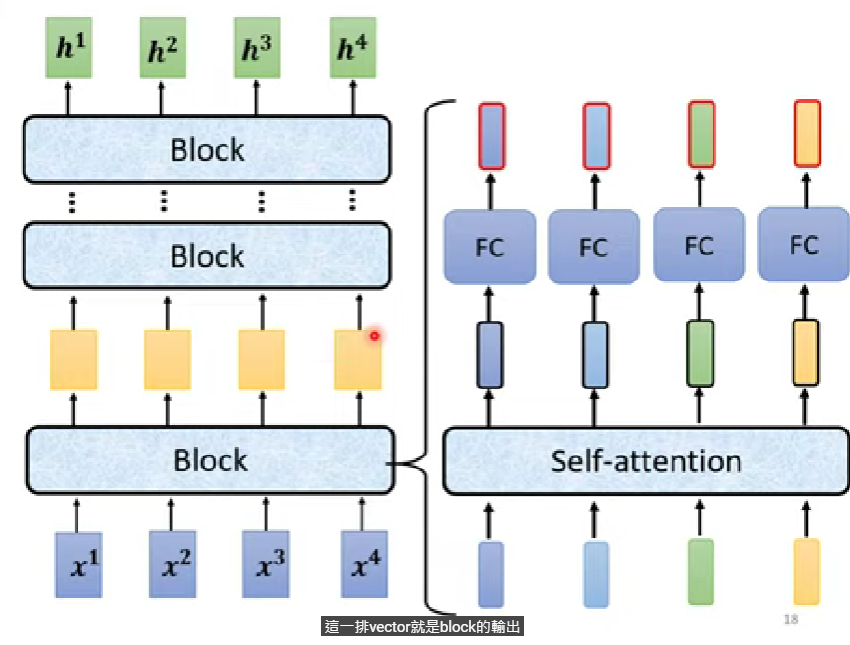
原本只有一層(就是self.encoder_layer),可以改成呼叫self.encoder並修改Classifier的forward
寫作業歷程 2022/7/22 這次作業transformer(self-attention)在NLP與語音辨識領域運用廣泛,是我想要好好學好的章節,不過這次作業給我挫敗感很大…comformer的paper ,但是因為對於transformer的觀念也不甚熟悉,所以照著李宏毅老師給的reference查到了這篇paper(中文心得版) ,在大略的瞭解了transformer家族以後,最後回去看了一下別人看「Attention is all you need」的心得 ,對照上課的筆記這才更有了概念
到了晚上終於要開始著手改code,首先在torchaudio document 查到了他支援的conformer model API,開始套用以後才開始發現他的問題:看似簡單的forward修改其實困難重重!
首先是最基礎的問題,因為是pytorch菜雞,我甚至連forward的意涵是什麼都不知道,後來查到原來他是__call__會呼叫的函數,通常進行一個step(單位為一batch)的計算,而這份code在訓練時會呼叫model_fn
model_fn用意在於model.forward()以及計算loss
搞懂了forward以後,開始著手修改forward內部的code使他貼合conformer,但因為這樣所以我也必須去查torchaudio.models.Conformer這個class裡面的forward會怎麼運作(巢狀模型),查到的資料如下:
1 2 # out: (batch size, length, d_model) self.encoder(out,(out[0],) )
這麼做跳了一個錯誤:他抓不到out[0]的shape,我這才發現他要的是torch.Tensor type,於是我改成
1 self.encoder(out, torch.tensor(out[0],) )
仔細研究torch.tensor用法以後終於可以正確地塞tensor進去,但是我卻鬼打牆的一直卡在lengths這個參數的shape不對,從錯誤碼發現跟ket_padding_mask有關,幾經波折以後看到這篇 才發現他要吃的參數是(batch size,sequence length),最後修正成了這樣
1 out = self.encoder(out,torch.tensor([out[0],out[1]]))
卻碰到了新的錯誤碼:
2022/7/23 果然是昨天腦袋昏到不好思考,把out.size(0)跟out[0].size()搞混,雖說後來修正了,但還是套不進去。對於tensor dim的掌握力太差了…
後來改用這個conformer 來實作,多了很多我不知道幹嘛用的參數,而且看似不能增加layer數orz…,先求能跑吧,感覺達不到strong base line了,參數如下
1 2 3 4 5 6 7 8 9 10 11 self.encoder_layer = ConformerBlock( dim = d_model, dim_head = 64, heads = 2, ff_mult = 4, conv_expansion_factor = 2, conv_kernel_size = 31, attn_dropout = 0., ff_dropout = 0., conv_dropout = 0. )
要注意的是他的forward吃的參數是(length, batch size, d_model),所以permute那行註解要拿掉,這方面沒有統一真的很煩人,最後Classifier forward code如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def forward(self, mels): """ args: mels: (batch size, length, 40) return: out: (batch size, n_spks) """ # out: (batch size, length, d_model) out = self.prenet(mels) # out: (length, batch size, d_model) out = out.permute(1, 0, 2) # The encoder layer expect features in the shape of (length, batch size, d_model). #out = self.encoder_layer(out) # Do 2 conformer layer # out = self.encoder_layer(out) out = self.encoder_layer(out) # out: (batch size, length, d_model) out = out.transpose(0, 1) # mean pooling stats = out.mean(dim=1) # out: (batch, n_spks) out = self.pred_layer(stats) return out
中間有個out = self.encoder_layer(out)被註解了,我原本是想說既然參數不能設定layer數,那就讓他跑兩次也可以是兩輪,不過我想太美了,因為GPU多線程的關係,讓整個tqdm的log大暴走,正確性也打個問號,搞不好會碰到race condition…,因為這是這個模型設計者沒設計到的部分(或是我菜到沒發現QQ),所以最後決定讓他就單層去跑
作業結果 Train了70000 step (大約1 hr),跟strong差一點點,但acc還在上升,感覺是練不夠久
1 2 3 4 5 if exists("./model.ckpt"): model.load_state_dict(torch.load("./model.ckpt")) print("Exist model detected, continue training...") if model.training() == False: model.train()
得到命中率=79%
但提交的時候卻出了大問題,測試的結果非常差
Report
因為卡住所以我有多看幾個varient
linformer : 藉由attention matrix在做sorftmax轉化以後非行滿秩的特性,降低attention matrix的維度,使得transformer的複雜度可以降到線姓
因為transformer雖然可以考慮sequence的全局性,但對於自己的重視程度較為有限,而CNN則可以對局部性的特徵著重關注,兩者混合起來可以達到互補提高準確性的效果。