機器學習總編首頁
台大李弘毅老師的課
2021年預習筆記
Ch 1:Introduction of Deep Learning
[1-1]監督式學習概論
- 介紹甚麼是機器學習,以及機器學習的任務
- 以預測李宏毅老師的頻道觀看人數為例,介紹監督式學習的運作流程
關鍵字:
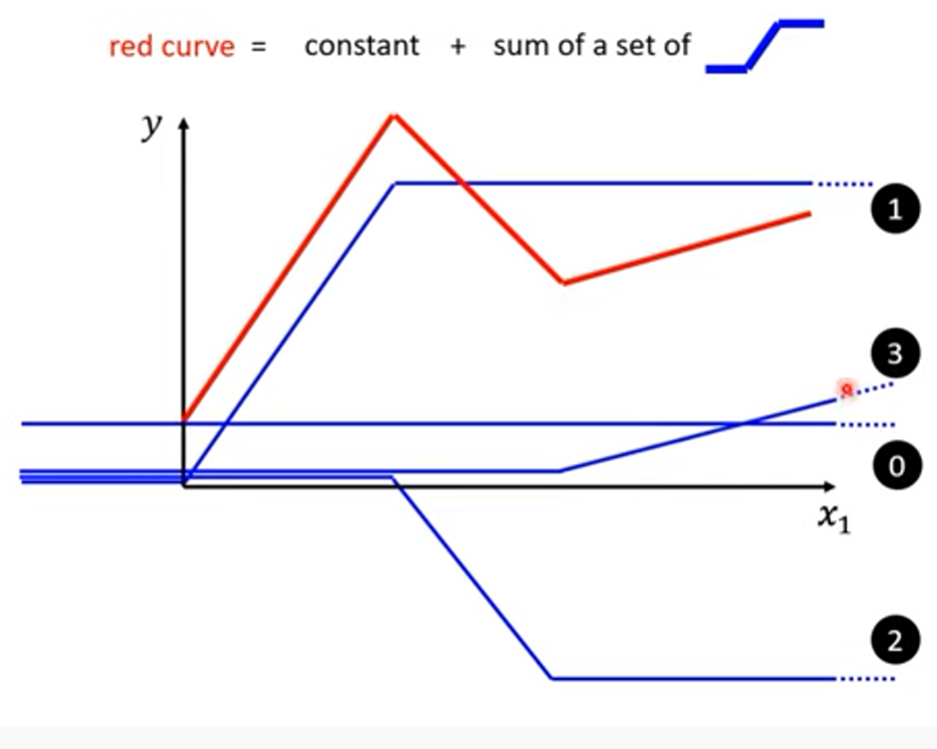
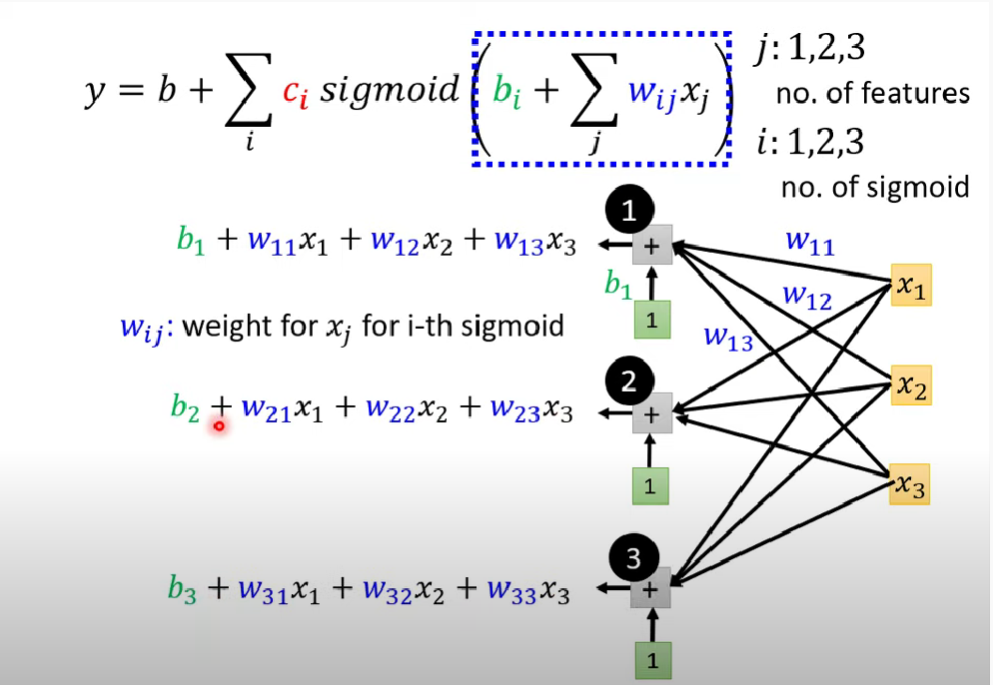
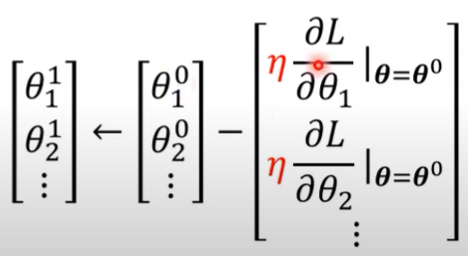
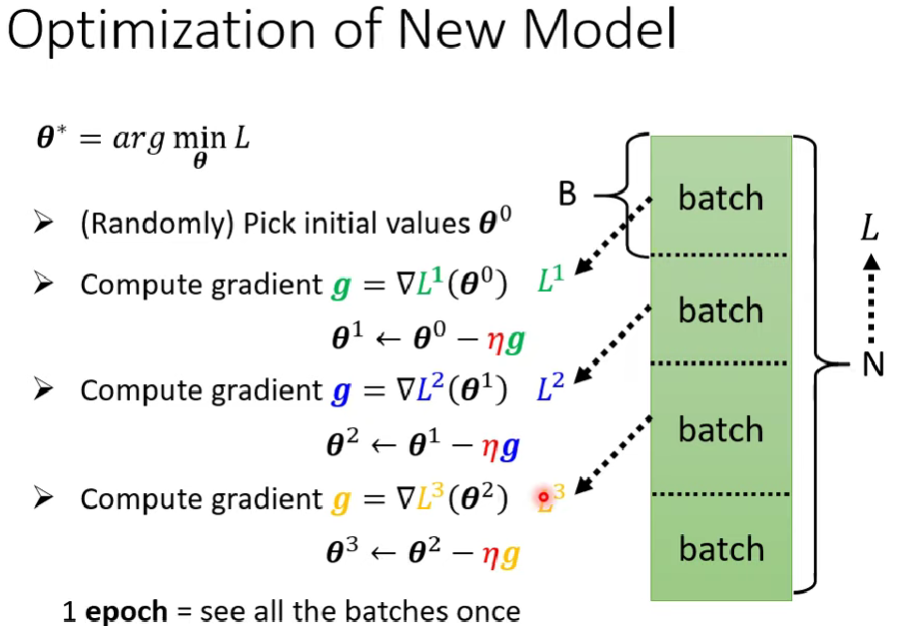
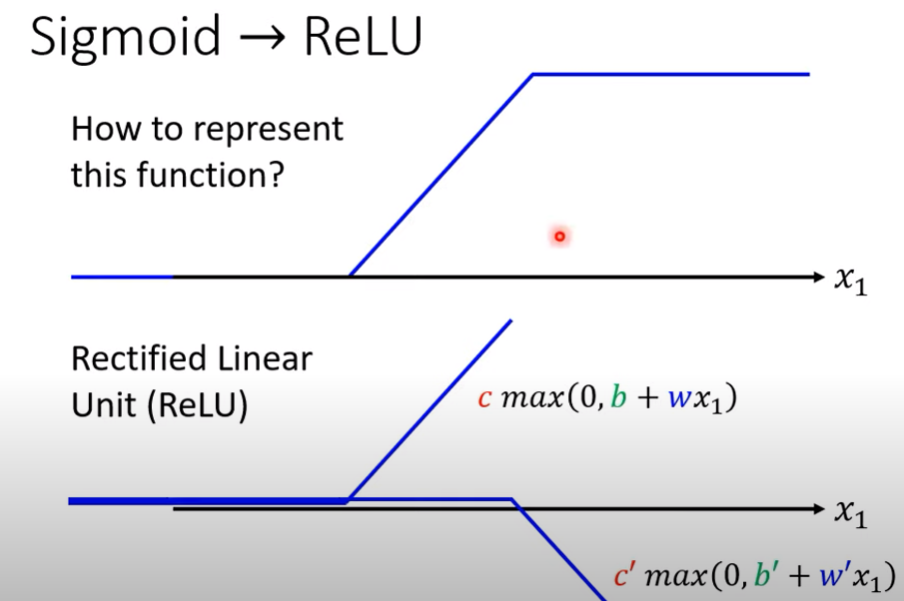
Linear model、Piecewise Linear Curve、sigmoid介紹、ReLU介紹、theta、Batch、Epoch
Ch 2:What to do if my network fails to train
[2-1]機器學習任務攻略
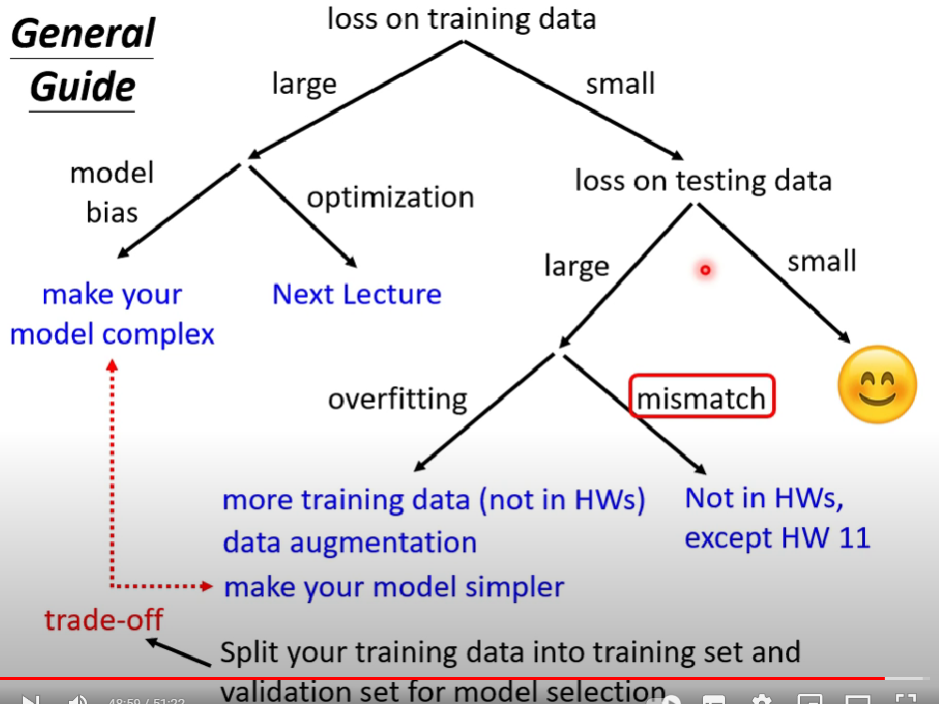
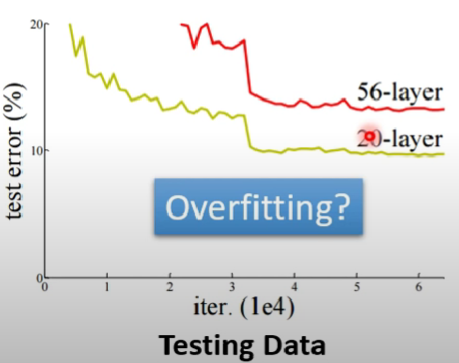
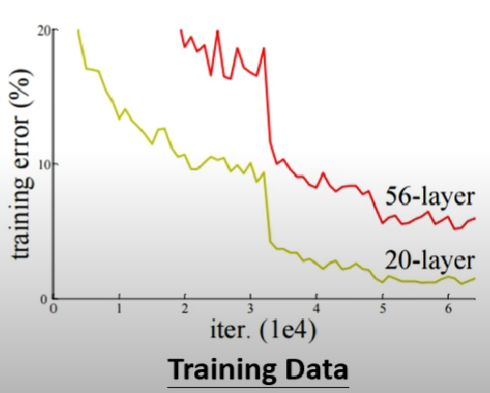
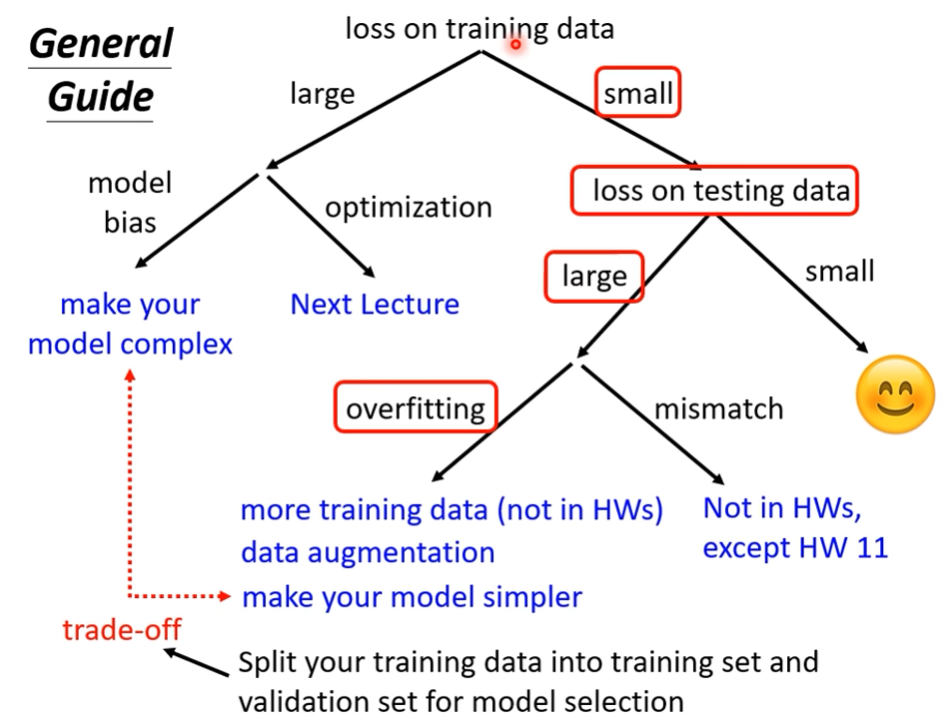
- 機器學習上可能碰到的疑難雜症介紹,以及如何改善
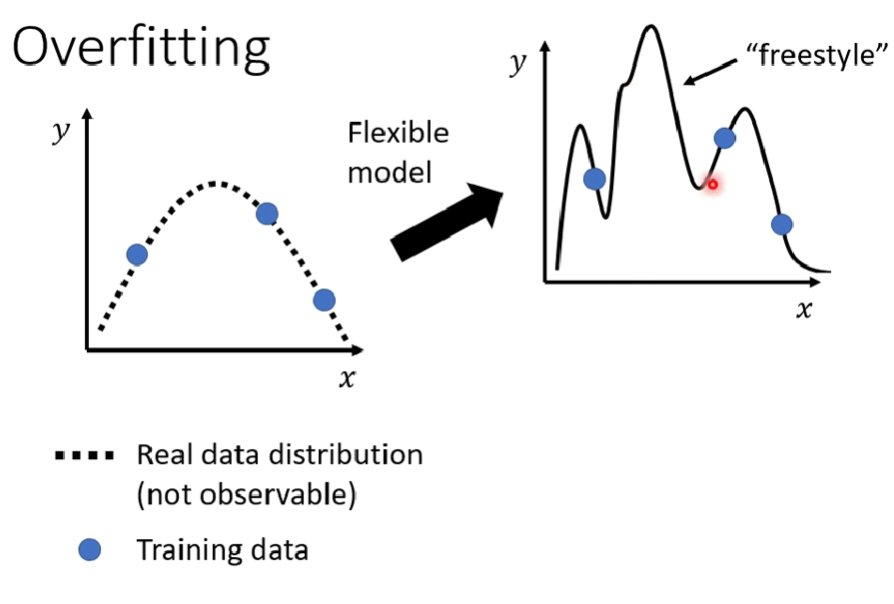
- 區分命中率問題到底是overfitting、model bias issue還是Optimization issue,甚至是data mismatch
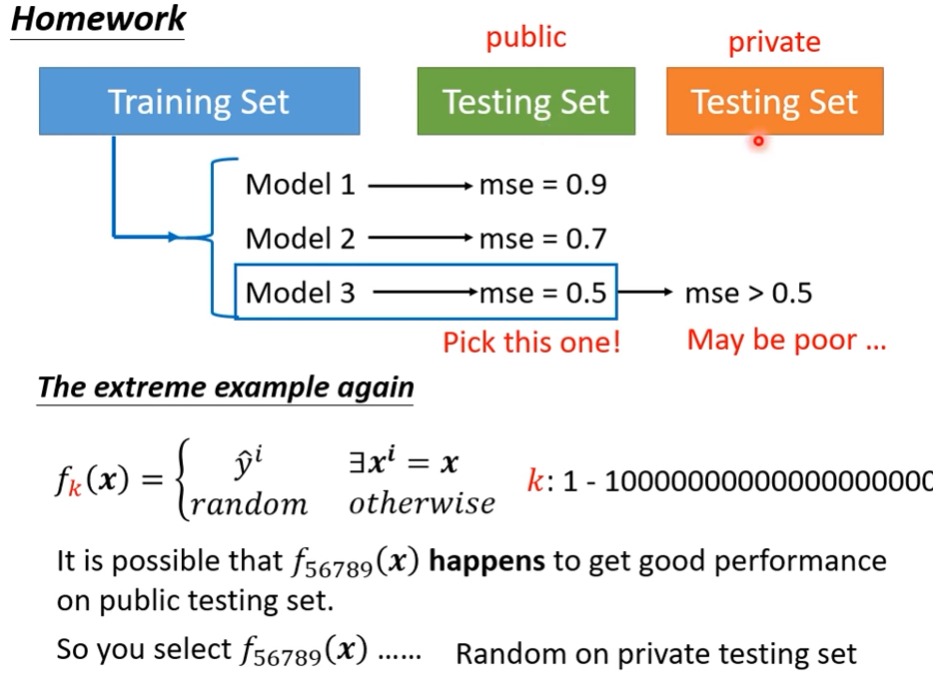
- 當一個模型單次測試test data成績很好,就保證是模型很好嗎? 如何更確保模型真的很好呢?
關鍵字:
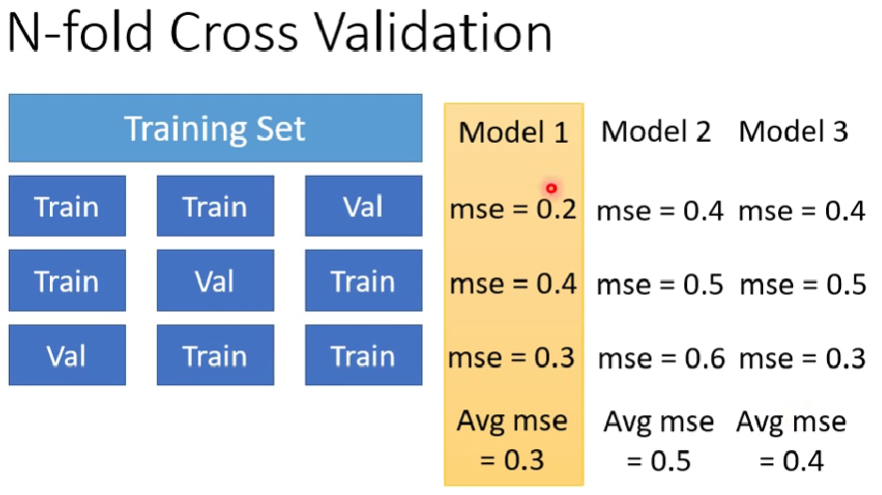
Overfitting , model bias issue , Optimization issue之分辨、N-fold Cross Validation、data mismatch
[2-2]類神經網路訓練不起來怎麼辦(一)
- 續2-1的大綱,專注在討論optimizer失靈的解決方法與成因分辨
- 提供一個應用線性代數的例子:如何讓一個卡在鞍點的$\theta$逃離鞍點 (但計算曠日廢時)
- loss function = MSE , optimizer = 梯度下降法
- 絕大多數的模型其實若卡在critical point,都是卡在鞍點而非局部最小值
關鍵字:
Optimization issue、critical point、saddle point、local minima、三體III:死神永生
[2-3]類神經網路訓練不起來怎麼辦(二)
- 續2021版1-1的內容,我們這次探討batch size對於training與testing有甚麼影響
- big batch size好還是small batch size好? 要看hyper para怎麼調以及對於訓練速度的需求
- 額外介紹另一個對抗saddle point或local minima的技術 : momentum(慣性)
關鍵字:
batch size、momentum
[2-4]類神經網路訓練不起來怎麼辦(三)
- 這次討論Optimizer中,關於Learning rate的問題
- 一個模型的跑動,常常碰到單一learning rate所會碰到的困境,所以我們需要可以隨著單次訓練中各種情況變動的learning rate
- 提供兩種改變learning rate的作法以及相關參數計算
- 簡單介紹這些手法被現今哪些熱門優化器使用
關鍵字:
Learning rate($\eta$)、Adaptive learning rate、Adam-learning rate、RMSProp、Warm up(learning rate)、learning rate decay
[2-5]類神經網路訓練不起來怎麼辦(四)
- 簡短介紹當碰到分類問題的時候,最後一層激發函數該選哪個函數
- 介紹了one-hot vector作為新的輸出型態,以及基本原因
- 介紹分類模型的常用loss function,以及用optimizer的角度看兩種loss function的差距
- 因為是簡短版,內附有
冗長版 完整版連結
關鍵字:
one-hot vector、Softmax、cross entropy
[2-6]類神經網路訓練不起來怎麼辦(五)
- 簡短介紹Batch Normalization的技術
- 這是另一種直接改變error surface的技術(相對於動態lr)
- 關於batch normalization為何能夠讓模型訓練更好仍是個謎
關鍵字:
Feature Normalization、Batch Normalization
[3-1]卷積神經網路
- 介紹CNN neurol network 以及他的相關常用術語
- 旨在讓我們了解CNN,一個入門指引
- 以CNN:apply in image為例,用於文字辨識或是語音辨識需要更多參考相關文獻,用於影像的CNN不一定適用其他輸入
關鍵字:
Receptive Field(Kernel size)、Filter、Parameter sharing、Pattern、Stride、Convolusion、Feature Map、Subsample (pooling)、padding(pads)、channel、(Rescale、data augmentation)
[4-1]自注意力機制(上)
- 介紹在碰到輸入的時候不只是一個向量,甚至可能輸入的向量數量會變動,該怎麼處理
- 簡單介紹輸入為sequence的常見問題以及不同輸出的類別
- 介紹如果輸入的sequence,不同vector之間互相影響該怎麽處理
- 本課程著重在討論sequence中每個vector都會有獨立一個label輸出的情況
關鍵字:
Sequence、word embedding、window(語音處理)、self-attention、transformer(提到)、seq2seq(提到)
[4-2]自注意力機制(下)
- 常用(上週討論的)self-attention計算方法,其實就是很多的矩陣相乘
- 當一個vector出現在sequence的不同位置也需要考量,該怎麼處理 -> Positional encoding
- 因為attention matrix之空間大小是$\theta(n^2)$,所以當sequence很大(ex.音訊)時,該怎麼處理 -> Truncated self-attention
- self-attention可否用於影像呢? 如果這樣使用的話,self-attention跟CNN差別在哪?誰優誰劣呢
- Self-attention與RNN之間的差別在哪
- self-attention如何使用在graph中呢?GNN是什麼呢(refrence)
- Reference各種transformer的變形(survey paper)
PS. 這塊領域目前很新,論文大多產自2019/2020年
關鍵字:
Transformer(self-attention塊)、positional encoding、truncation self-attention、v.s CNN、v.s RNN、GNN
Ch5:Sequence 2 Sequence
- 算是Ch4中的一種特例輸入
- 5-1就是2-6,介紹batch norm
[5-2]Transformer(上)
- 首先講解seq2seq類模型所可以解決的問題與應用,接下來講解seq2seq的其中一種模型「transformer」
- 介紹transformer的大架構圖,以及transformer encoder的分解步驟
- 除了原始的transformer encoder模型圖以外,還有reference其他種transform encoder的架構
- BERT其實就是transformer的encoder
關鍵字:
Transformer(總覽 & encoder)、seq2seq類應用
[5-3]Transformer(下)
- 接續5-2,介紹原始Transformer decoder之詳細步驟,以及計算loss的方式
- 介紹為何transformer的loss function要用cross entropy,而不能直接用如BLEU等等判別算法,並說明他們兩者之間並不一定正相關
- Transformer依decoder訓練方式有分為AT與NAT,本課主要講姊AT
- 介紹Seq2Seq常見的一些training技巧與問題
關鍵字:
Transformer(decoder、loss)、AT & NAT、Scheduled Sampling、Beam search、Teacher forcing、Copy mechanism、Guided Attention
Ch6:Generation (Generative Adversarial Network, GAN)
[6-1]生成式對抗網路(一) – 基本概念介紹
- 介紹GAN的訓練過程、用途、基本原理
- GAN變種非常多
這集超油
關鍵字:
discriminator、generator、Train GAN process、GAN zoo
[6-2]生成式對抗網路(二) – 理論介紹與WGAN
- 介紹Discriminator與Generator如何訓練
- true data跟generated data之distribution差距過大,原本的JS GAN discriminator很難evaluate
- WGAN的discriminator算法與reference
Note:這部看不是很懂,要複習
關鍵字:
WGAN、Wasserstein distance、1-Lipschitz function(待查)
[6-3]生成式對抗網路(三) – 生成器效能評估與條件式生成
- 續6-2,貼了一些關於GAN training tips的延伸學習
- GAN + Transformer (GAN in sequence generation)
- 除了GAN以外,還有哪些也是在做generation的model
- GAN的優劣如何衡量? 會有哪些問題被忽略?
- Conditional GAN(把開頭GAN被拔掉的x放回來了)
- Conditional GAN相關天馬行空的應用
關鍵字:
VAE、FLOW-based Model、Mode Collapse、Mode Dropping、Inception score(IS)、Frechet inception distance(FID)、Conditional Generation
[6-4]生成式對抗網路(四) – Cycle GAN
- 以影像風格轉換為例,說明cycle GAN如何應用在unsupervised learning上面
- reference 可以接受更多風格的非監督式GAN
- 介紹其他更多任務的GAN unsupervised learning (撇除圖片)
Note: 有一些地方觀念模糊,為何generator輸出是文字,丟給discriminator會出現問題?為何需要用RL?
關鍵字:
cycle GAN 、GAN unsupervised learning、seq2seq generator unsupervised learning
Ch 6.5 :Recent Advance of Self-supervised learning for NLP
以BERT、GPT為例介紹近期self-supervised learning model的原理與在NLP上的應用
[X-1 & X-2]自督導式學習(一、二) – BERT簡介
- 簡介BERT的訓練(pretrain)方法,以及一些應用
- how to fine-tune BERT in some cases.
- 帶一下pretrain decoder的方法
關鍵字:
Fine-tune、pretrain (Next sentence prediction、sentence order prediction(SOP)、masking input)
[X-3]自督導式學習(三) - BERT的奇聞軼事
[X-4]自督導式學習(四) – GPT的野望
- 介紹另一個self-supervised learning model:GPT
- GPT的任務目標比起BERT更加有野心:期望能夠輸入task description與問題,就能自己預測出答案
- GPT的訓練方式類似transformer的decoder,給定一個seq,要能預測下一個token是甚麼
關鍵字:
GPT
Ch8:Auto-encoder/ Anomaly Detection
[8-1]自編碼器(上) – 基本概念
- 介紹auto-encoder的模型,以及它的學習任務
- auto-encoder跟現今cycle GAN的2 generator關係很像
- 介紹de-noising auto-encoder,並且分析它與現今的self-supervised learning model(BERT)的相似
- auto-encoding 具備降維壓縮的功能
關鍵字
de-noising auto-encoder、embedding(Representation, Code)、dimention reduction
[8-2]自編碼器(下) – 領結變聲器與更多應用
- 柯南的領結變聲器,就是一種voice conversion的應用。現實中要做到這一點,就需要對embedding有更多理解 – Feature Disentanglement
- 除了傳統的auto-encoder之外,還有各種auto-encoder的變形
- embedding(representation)的各種花招以及模型修改
- auto-encoder的更多應用,比如本次作業會用到的異常檢測
關鍵字
Feature Disentanglement、Discrete Latent Representation、Text/Tree as Representation、VAE、Anomaly Detection
Note:
8-3 ~ 8-8 是Anomaly Detection主題的內容
第一部影片連結
這裡先略過
Ch9:Explainable AI
[9-1]機器學習模型的可解釋性(上) – 為什麼類神經網路可以正確分辨寶可夢和數碼寶貝呢?
- 為何需要可解釋性的AI? 對於AI可解釋的標準定義是?
- 可解釋性AI的類型
- 要能找出一個輸入的哪個部位重要,有哪些技巧?
- 要能看出機器怎麼對輸入做處理,有那些技巧?
關鍵字:
local/global explanation、Saliency map、SmoothGrad、Visualization、Probing
[9-2]機器學習模型的可解釋性(下) – 機器心中的貓長什麼樣子?
- 著重在global explainable的各種approach
- 觀察convoluation layer output
- 看classifier output
- 做一個簡易版可解釋的model模仿他的行為
Ch10:Adversarial Attack
[10-1]來自人類的惡意攻擊(上) – 基本概念
- 介紹攻擊的原理、作法之精神
- 常見attack相關限制的介紹與計算方式
- 實際攻擊的一種approach method
關鍵字:
benign image/attacked image、FGSM
[10-2]來自人類的惡意攻擊(下) – 類神經網路能否躲過人類深不見底的惡意?
- 除了白箱攻擊以外,講解黑箱攻擊的技巧
- 簡單探討為何黑箱攻擊具有可行性 -> 資料的特徵問題,而非模型?
- 可攻擊的領域與方法
- 如何防禦黑箱攻擊
關鍵字:
Proxy network、Ensemble attack、One pixel attack、Universal Adversarial Attack、Adversarial reprogramming、Backdoor in model、被動:Randomization、主動:Adversarial training、、、、、、
Ch11:Adaptation
[11-1]概述領域自適應
- 概述何為Domain shift
- Domain adaptation名詞解釋
- 根據condition的不同(target,source差距、手握的data量),簡單講解domain adaptation的各種approach
- 本課著重在target domain unlabeled data很多的前提
- 提供各種condition的參考文獻(列入關鍵字)
關鍵字:
source/target domain、Domain Adversarial training、Feature Extractor、Domain Classifier、Label Predictor、Universal domain adaptation、Testing time training、Domain Generalization
CH12:Reinforcement Learning
[12-1]概述增強式學習(一) – 增強式學習跟機器學習一樣都是三個步驟
2022年正課筆記
[1-1]正課內容介紹
- 介紹各講的重點核心
- $X-y$中的X對應的是第幾講,2021年的編號也同樣,是按造課程網頁的syllabus排的
[2-1]再探寶可夢、數碼寶貝分類器
作業區(有寫的部分orz)
作業3 - 圖像辨識,使用CNN
作業4 - 語音辨識,使用Transformer
作業5 - Transformer
作業6 - GAN
作業7 - BERT